推荐系统:recommendation system
1 推荐系统背景
为了解决 信息过载 问题,在海量的数据中如何准确提供客户喜欢的内容。为了解决该问题,发展主要有三个阶段。
- 分类目录:1990s Hao 123 Yahoo
- 搜索引擎:2000s Google Baidu
- 推荐系统:2010s 不需要客户提供准确的信息,通过分析客户的历史行为来进行对用户的兴趣建模,从而提供客户满意的信息。
2 推荐和搜索的区别
- 搜索引擎:由用户主导,需要输入关键词,自行选择结果。如果结果不满意,需要修改关键词,再次搜索;注重搜索结果之间的关系和排序。
- 推荐系统:由系统主导,根据用户的浏览顺序,引导用户发现自己感兴趣的信息,需要研究用户的兴趣模型,利用社交网络的信息进行个性化的计算;
3 推荐系统的意义
主要有三个意义,分别从用户,内容提供者,平台
- 让用户更好的获取自己需要的内容
- 让内容更快更好的推动到适用人群
- 让平台跟有效的保留用户资源

4 推荐系统的应用

5 基本思想
- 知你所想,精准推送
利用用户和物品的特征信息,推荐具有这些特征的信息 - 物以类聚
利用用户喜欢的物品,推荐类似的物品 - 人以群分
利用和用户相似的其他用户,基于他们的特征进行推荐
6 数据源
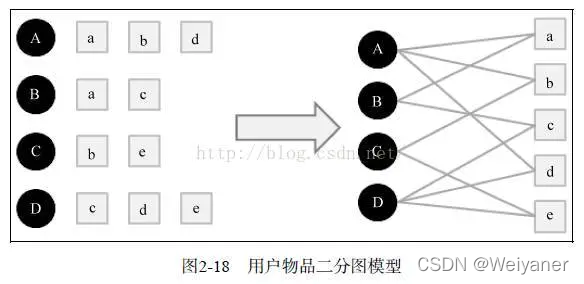
三类数据源: 用户,物品,行为数据
-
item数据:待推荐物品或内容的元数据,例如关键字,分类标签,基因描述等;
-
User 数据:用户的基本信息,例如性别,年龄,兴趣标签等;
-
行为数据:可以转化为对物品或者信息的偏好,根据应用本身的不同可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。这些用户的偏好信息可以分为两类:
- 显式的用户反馈:用户在网站上显式的反馈信息,例如用户对物品的评分,对物品的评论。
- 隐式的用户反馈:用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。

7 推荐系统的分类
1.根据实时性分类
- 离线推荐
- 实时推荐
2 是否个性化推荐
- 基于统计的
- 个性化推荐
3 根据推荐原则分类
- 基于相似度
- 基于知识
- 基于模型
4 根据数据源
- 基于人口统计学(用户信息)
- 基于内容的推荐(商品信息)
- 基于协同过滤的推荐 (基于行为数据)

1.基于人口统计学:

2.基于内容(Content Based,CB):
主要是利用用户评价过的物品内容的特征,CF还可以利用其他用户评价过的物品内容。
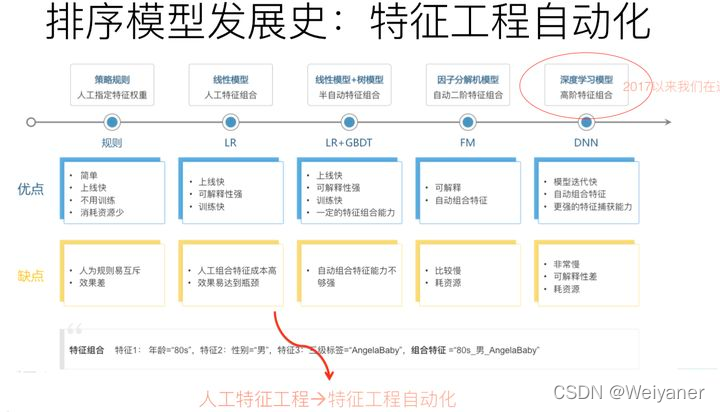
3.基于协同过滤:collaborative filtering,CF
- 基于近邻的协同过滤
- 基于用户(User-CF)
- 基于物品(Item-CF)
- 基于模型的协同过滤
- 奇异值分解(SVD)
- 潜在语义分解(LSA)
- 支持向量机(SVM)
4.混合推荐,就是集成学习(ensemble learning)
- 加权混合
对不同的推荐结果按照权重线性加权 - 切换混合
多套推荐机制,根据系统的不同情况选择最合适的推荐机制 - 分区混合
采用多种推荐机制,将不同的推荐结果推送到不同的用户 - 分层混合
采用多种推荐机制,将一个机制的推荐结果作为另外一个的输入,类似boosting,串行学习??
下一篇:推荐系统(2)——评测指标