文章目录
- 1 AutoRec——神经网络推荐算法的开端
- 1.1 自编码器
- 1.2 AutoRec模型结构
- 1.3 AutoRec的推荐过程
- 1.4 模型的特点和局限
- 2 Deep Crossing——深度学习推荐算法的完整应用
- 2.1 Deep Crossing的应用场景
- 2.2 Deep Crossing的模型结构
- 1 特征
- 2 网络结构
- 2.3 Deep Crossing的革命性意义
- 3 Neural CF——CF+深度学习
- 3.1 深度学习的视角看矩阵分解模型
- 3.2 Neural CF的模型结构
- 3.3 Neural CF的评价
- 4 PNN——特征交叉的进一步加强
- 4.1 PNN的网络结构
- 4.2 PNN的多种特征交叉方式
- 1 内积操作
- 2 外积操作
- 4.3 PNN的优势与缺点
- 5 Wide&Deep——记忆和泛化能力的综合
- 5.1 模型应用的场景
- 5.2 记忆能力和泛化能力
- 5.3 Wide&Deep模型结构
- 1 Deep部分
- 2 Wide部分
- 5.4 Wide&Deep的进化——DeepCrossNetwork(DCN,Stanford,2017)
- 5.5 Wide&Deep的评价
- 6 FNN,DeepFM,NFM—— FM+深度学习
- 6.1 FNN——FM的隐向量作为Embedding层初始化
- 6.2 DeepFM——用FM代替Wide部分
- 6.3 NFM——FM的神经网络尝试
- 1 NFM模型结构
- 2 另一个视角解读——Wide&Deep的Deep改进
- 6.4 基于FM和深度学习的模型评价
2015年澳大利亚国立大学提出了AutoRec,看作是推荐领域第一个神经网络推荐模型。
2016年则是深度学习遍地开花的一年,相继提出了FNN,DeepCrossing,FFM,wide&deep等一系列的影响力巨大的大模型,因此可以看作2016年是与推荐系统/计算广告进入深度学习时代的开端。
推荐算法发展路线如下:

1 AutoRec——神经网络推荐算法的开端
Autorec: Autoencoders meet collaborative filtering
AutoRec是一个典型的自编码器,基本原理是通用协调过滤的共现矩阵完成物品或者用户信息的自编码,再根据自编码信息进行预估评分,完成推荐。
1.1 自编码器
自编码器就是完成数据实现自动编码的模型,可以实现对图像,音频,或者文本数据到向量数据的映射。
对于输入向量r,通过重建函数 h ( r ; θ ) h(r ; \theta) h(r;θ),得到自编码向量,目标函数如下:
min θ ∑ r ∈ S ∥ r − h ( r ; θ ) ∥ 2 2 \min _{\theta} \sum_{r \in S}\|r-h(r ; \theta)\|_{2}^{2} θminr∈S∑∥r−h(r;θ)∥22
一般来说,自编码器的重建函数的参数远小于输入向量的维度,因此可以实现数据的压缩和降维。得到的自编码向量也完全等价于输入向量,所以具备了一定缺失维度的预测能力。也是为什么自编码器用在推荐的原因。
1.2 AutoRec模型结构
他是一个最简单的的三层神经网络结构,包括输入,隐含层和输出层。

图中的
V
V
V 和
W
W
W 分别代表输人层到隐层, 以及隐层到输出层的参数矩阵。该 模型结构代表的重建函数的具体形式如 (式 3-2) 所示。
h
(
r
;
θ
)
=
f
(
W
⋅
g
(
V
r
+
μ
)
+
b
)
h(\boldsymbol{r} ; \theta)=f(\boldsymbol{W} \cdot g(\boldsymbol{V} \boldsymbol{r}+\mu)+b)
h(r;θ)=f(W⋅g(Vr+μ)+b)
其中,
f
(
⋅
)
,
g
(
⋅
)
f(\cdot), g(\cdot)
f(⋅),g(⋅) 分别为输出层神经元和隐层神经元的激活函数。为防止重构函数的过拟合, 在加人 L2 正则化项后, AutoRec 目标函数的具 体形式如 (式 3-3) 所示。
min
θ
∑
i
=
1
n
∥
r
(
i
)
−
h
(
r
(
i
)
;
θ
)
∥
0
2
+
λ
2
⋅
(
∥
W
∥
F
2
+
∥
V
∥
F
2
)
.
\min _{\theta} \sum_{i=1}^{n}\left\|\boldsymbol{r}^{(i)}-h\left(\boldsymbol{r}^{(i)} ; \theta\right)\right\|_{0}^{2}+\frac{\lambda}{2} \cdot\left(\|\boldsymbol{W}\|_{F}^{2}+\|\boldsymbol{V}\|_{F}^{2}\right) .
θmini=1∑n∥∥∥r(i)−h(r(i);θ)∥∥∥02+2λ⋅(∥W∥F2+∥V∥F2).
由于 AutoRec 模型是一个非常标准的三层神经网络, 模型的训练利用梯度反 向传播即可完成
1.3 AutoRec的推荐过程
要通过自编码器,我们输入物品i的评分向量
r
(
i
)
r^{(i)}
r(i),进而得到了输出向量
h
(
r
(
i
)
;
θ
)
h(r^{(i)};\theta)
h(r(i);θ)。也就是所有用户对于物品i的评分预测情况,那么第u个就是用户u对物品i的评分预测,记作:
R
^
u
i
\hat R_{ui}
R^ui.
R
^
u
i
=
(
h
(
r
(
i
)
;
θ
^
)
)
u
\hat{R}_{\mathrm{ui}}=\left(h\left(\boldsymbol{r}^{(\mathrm{i})} ; \hat{\theta}\right)\right)_{u}
R^ui=(h(r(i);θ^))u
对整个物品向量进行遍历,就得到了所用物品的评分预测结果,进而得到推荐list。
和协同过滤过滤一样,也分为基于物品(Item based AutoRec)和基于用户的自编码(User based AutoRec)。上面讲述的就是基于物品的AutoRec模型推荐。在推荐列表生成的过程中,基于用户的好处在于仅需要输入一次目标用户的输入向量即可以得到对所以物品预测评分,但是带来的缺点就是用户向量的稀疏性可能对模型精度有影响。
1.4 模型的特点和局限
通过神经网络模型,使用一个单隐层的Auto Encoder对用户/物品评分进行编码,模型具有一定的泛化和表达能力
但是由于模型过于简单,带来的就是表达能力不足问题。
在模型结构上,与词向量模型word2vec模型一致,区间在于优化目标和训练方法的不同。
2 Deep Crossing——深度学习推荐算法的完整应用
Deep crossing: Web-scale modeling without manually crafted combinatorial features
如果说AutoRec是深度学习在推荐系统的初步尝试,那么deepcrossing就是一次深度学习的完整应用,由微软公司于2016年提出,,完整的解决了从特征工程,稀疏向量稠密化,多层神经网络进行优化目标拟合等一系列应用问题
2.1 Deep Crossing的应用场景
应用于微软搜索引擎Bing的搜索广告推荐业务中,在用户输入搜索词后,返回一系列搜索目标和相关的广告,通过提升广告的点击率来进行盈利。因此对广告的CTR预测就成了非常重要的工作,这就是本算法的优化目标。
2.2 Deep Crossing的模型结构
1 特征
针对以上的广告CTR任务,微软使用以下特征,主要分成三类
| 序号 | 类别 | 特征 |
|---|---|---|
| 1 | 类别型特征:可以处理为one-hot/multi-hot | 用户搜索词query//广告关键词keyword//广告标题title//落地页//landing page//匹配类型match type |
| 2 | 数值型 | 点击率//预估点击率clic Prediction |
| 3 | 进一步处理的特征 | 广告计划campaign//曝光样例impression//点击样例click |
类别型的特征可以通过one-hot,数值型可以进行拼接。
2 网络结构
为了实现端到端的训练,Deep Crossing完成了以下任务:
- 离散类特征向量的one-hot编码过于稀疏,如何进行稠密化?
- 如何解决特征的自动交叉问题
- 如何在输出层实现设定的优化目标
根据以上问题,设计了以下的网络结构:

主要分为:
-
Embedding层
将稀疏的类别型特征转为稠密的Embedding向量,比如Figure #1。一般来说,Embedding向量的维度远远小于原始的稀疏向量,一般为几十到几百。数值型特征不需要经过Embedding,直接进入Stacking层。
关于Embedding,后续会专门开一个文章介绍。这是深度学习很重要的一部分。
-
Stacking层
作用很简单,对于Embedding向量和数值型向量进行拼接,形成全部的特征向量,也被称为连接层。 -
Multiple Residual units层
主要结构为多层感知机,这里采用了多层残差网络(multiple-Layer Residual Network)作为MLP的具体实现,这里也是残差网络在推荐系统的成功应用。关于残差神经网络。
输入通过一个shortcut通路直接将RELU全连接层连接,进行元素加操作,在这样的结构下,实际上拟合的是输入与输出之间的残差,这也是残差神经网络的由来。在这里通过多多层残差神经网络对进行充分的自动交叉组合,使得模型学习到更多的非线性特征组合信息,增强其表达能力。
-
Scoring层
对于CTR这样的二分类模型,常使用LR这样的模型,因此选择对数损失函数进行优化。如果是进行多分类,则使用softmax模型。
2.3 Deep Crossing的革命性意义
放在如今看来,DeepCrossing并没有很高深的技巧,没有如今大盛的注意力机制,序列模型等等。但是放在当时那个年代,‘Embedding+多层神经网络’是有着革命性意义的,他是第一次没有加入人工特征,完全是实现了从原始特征到预测结果的end2end的过程,将全部特征交叉的任务交给模型。
相对于之前的FM,FFM只具备二阶交叉特征的能力,DC可以通过调整神经网络的深度对特征进行深度交叉,这也是deep crossing的由来。
3 Neural CF——CF+深度学习
Neural Collaborative Filtering (NUS 2017)
深度学习之前的协同过滤模型可谓是推荐系统的一片天,在CF的基础上,有进一步衍生了矩阵分解的思想,进一步,在2017年,新加坡国立大学提出了基于深度学习的CF模型。从深度学习的视角重新审视矩阵分解。
3.1 深度学习的视角看矩阵分解模型
在矩阵分解中(关于矩阵分解),通过将共现矩阵分解为用户矩阵和物品矩阵的内积形式,从而得到用户u对物品i的评分预测,这里分解得到的隐向量可以看作是一种embedding的形式,然后内积可以看作是Scoring层。
r
^
r
i
=
p
u
q
i
T
\hat r_{ri}=p_uq_i^T
r^ri=puqiT
使用神经网络来进行描述就是:

由于采用内积的方式进行评分预测过于简单,也造成矩阵分解有点欠拟合。在这基础上,采用多层神经网络+输出层来进行改善矩阵分解。
3.2 Neural CF的模型结构
通过采用多层神经网络+输出层替代了简单的内积操作。让用户向量和物品向量进行充分的交叉组合,增加模型的表达能力,

在输出层主要是使用softmax函数+cross entropy损失函数实现n分类,可以看我这篇文章:softmax和交叉熵的来龙去脉
3.3 Neural CF的评价
提出了以恶搞框架模型,基于用户和物品向量这两个embedding层,利用不同的互操作进行特征交叉,并灵活的进行不同互操作层的拼接。
优势:
- 神经网络理论上可以拟合任意函数
- 可以灵活的进行特征交叉,按需增加/减少模型的复杂度
缺点:
- 基于协调过滤的思想,本质上没有引用其他类型的特征,没有充分利用其他的信息(上下文之类的)。
4 PNN——特征交叉的进一步加强
Product-based Neural Networks for User Response Prediction (SJTU 2016)
在上文的Neutral CF中,采用多层神经网络代替CF中的内积操作,如果使用更多的特征(不仅仅是物品和用户向量),该如何设计特征交互的方法呢?
2016年,上交提出了PNN模型,给了特征交互的几种设计思路。
4.1 PNN的网络结构
相比于DeepCrossing的网络结构,PNN在embedding,多层神经网络,输出层都没有太多的区别,唯一的区别在于Stacking层,deepcrossing使用简单的拼接作为连接层,而在PNN里面,选择了乘积层,不再是简单得拼接,而是使用Product两两交互,更加针对性的获取特征之间的交互信息。
相比于Neural CF,PNN不仅仅使用了物品和用户作为特征,选择了更多的特征通过Embedding编码生成同等长度的稠密Embedding向量。

4.2 PNN的多种特征交叉方式
PNN的创新主要在于引入了乘积层,主要分为两个部分:
- 线性部分z:对特征进行线性拼接
- 乘积部分p:对特征进行乘积操作,主要分为内积和外积操作
1 内积操作
内积就是经典的内积运算,设输入特征f1,f2,则:
g
i
n
n
e
r
(
f
1
,
f
2
)
=
<
f
1
,
f
2
>
g_{inner}(f_1,f_2)=<f_1,f_2>
ginner(f1,f2)=<f1,f2>
2 外积操作
外积操作实对两个特征的各维度进行交叉,生成一个MxM矩阵,M是特征的维度。定义为:
g
o
u
t
e
r
(
f
1
,
f
2
)
=
f
1
f
2
T
g_{outer}(f_1,f_2)=f_1f_2^T
gouter(f1,f2)=f1f2T
外积操作无疑将复杂度由原来的M提升到了 M 2 M^2 M2,论文终也提出了一种降维的方式。就是将外积操作得到的矩阵进行叠加,得到一个互操作矩阵p:
p = ∑ i = 1 N ∑ j = 1 N g o u t e r ( f i , f j ) = ∑ i = 1 N ∑ j = 1 N f i f j T = f ∑ f ∑ T , 其 中 f ∑ = ∑ i = 1 N f i p=\sum_{i=1}^{N}\sum_{j=1}^{N}g_{outer}(f_i,f_j)=\sum_{i=1}^{N}\sum_{j=1}^{N}f_if_j^T=f_{\sum}f_{\sum}^T,其中 f_{\sum}=\sum_{i=1}^Nf_i p=i=1∑Nj=1∑Ngouter(fi,fj)=i=1∑Nj=1∑NfifjT=f∑f∑T,其中f∑=i=1∑Nfi
可以看作是对特征embedding向量通过了一个平均池化层,在进行外积操作,实际上,平均池化的操作需要谨慎,因为不用特征代表不同含义,比如年龄和地域的embedding向量明显不在一个空间,进行平均池化会造成很多信息的损失与模糊。
4.3 PNN的优势与缺点
- 强调了特征之间的交叉方式是多样化的,内积和外积针对性的强调了不同特征之间的交互,使得模型更容易捕获特征得交叉信息
局限:
- 外积操作带来了复杂度提升,为了优化采用平均池化带来了信息丢失
- 所有特征无差别交叉忽略了原始特征有价值的信息。
如何综合原始特征以及交叉特征,后续的wide&deep给出了解决方案。
5 Wide&Deep——记忆和泛化能力的综合
Wide & Deep Learning for Recommender Systems (Google 2016)
2016年,谷歌提出了影响力巨大的模型Wide&Deep,由单层的Wide层和多层神经网络Deep层构成的,前者让模型具有较强的记忆能力,后者让模型具有较强的泛化能力。使得模型兼具了LR和深度神经网络的优点。
- 既可以快速记忆大量的历史行为特征
- 还可以具有强大的表达能力
诞生以来就成为业界的主流模型,影响力延续至今。
5.1 模型应用的场景
该模型是由谷歌应用商店Google Pay推出的,主要应用在app的推荐上面。
5.2 记忆能力和泛化能力
记忆能力:模型直接学习和利用历史数据中的特征的能力。
一般认为简单模型如CF,LR有较好的记忆能力。。因为这类模型的结构简单,原始数据特征即可以直接影响预测结果,这相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
泛化能力:理解为模型传递特征的相关性,以及挖掘稀疏声之未出现过的隐特征与标签相关性的能力。。
矩阵分解就比CF的泛化能力要强,因为引入了隐变量表达之后,使得用户物品非常稀疏的数据也可以生出成隐变量,从而获得推荐,将全局数据传到稀疏物品上,从而提高了泛化能力。以及深度网络的特征多次交叉组合,挖掘数据中的潜在表达,即使是非常稀疏的数据也可以得到较为平稳的推荐概率。
5.3 Wide&Deep模型结构
通过将简单模型和深度网络结合,就使得模型同时具备了记忆能力和泛化能力。模型结构如下:

进一步,看看它的详细结构:

1 Deep部分
Deep 部分的输人有两种特征,
-
数值型的特征向量 包括:
- 用户年龄 (Age )
- 已安装应用数量 ( #App Installs )
- 参与会话数量(Engagement sessions)等等
-
类别型特征:
- 用户人口特征
- 设备类型 (Device Class )
- 已安装应用 ( User Installed App )
- 曝光应用 (Impression App ) 等特征
对于类别型特征,首先输入到Embedding层,获得稠密化的Embedding向量,随后和数值型特征一起输入到连接层,拼接为1200维度的向量。再依次经过三层Rule全连接层,最终输入到LogLoss输出层。
2 Wide部分
Wide层仅仅是已安装应用和曝光应用两个特征。这两个特征经过交叉积变换,公式如下:
∅ κ ( X ) = ∏ i = 1 d x i c k i c k i ∈ { 0 , 1 } \emptyset_{\kappa}(X)=\prod_{i=1}^{d} x_{i}^{c_{k i}} \quad c_{k i} \in\{0,1\} ∅κ(X)=i=1∏dxickicki∈{0,1}
c k i c_{k i} cki 是一个布尔变量, 当第 i i i 个特征属于第 k k k 个组合特征时, c k i c_{k i} cki 的值为 1 , 否 则为 0 ; x i 0 ; x_{i} 0;xi 是第 i i i 个特征的值。例如, 对于 “AND(user_installed_app=netflix, impression_app=pandora)" 这个组合特征来说, 只有当 “user_installed_app=netflix” 和 “impression_app=pandora” 这两个特征同时为 1 时, 其对应的交叉积变换层的 结果才为 1 , 否则为 0 。
在通过交叉积变换层操作完成特征组合之后, Wide 部分将组合特征输人最终的 LogLoss 输出层, 与 Deep 部分的输出一同参与最后的目标拟合, 完成 Wide 与 Deep 部分的融合
5.4 Wide&Deep的进化——DeepCrossNetwork(DCN,Stanford,2017)
Deep & Cross Network for Ad Click Predictions (Stanford 2017)
Wide&Deep的提出综合了记忆能力和泛化能力,还提供了不同网络结构之间的融合思路,更多的工作分别用来改进Wide或者Deep部分,斯坦福和谷歌在2017年提出了deepcrossnetwork,简称DCN。
主要思路是使用Cross来替代原先的Wide部分
 在CrossLayer中,为了增加特征的交叉力度,对特征进行了串行多次交叉,方式如下:
在CrossLayer中,为了增加特征的交叉力度,对特征进行了串行多次交叉,方式如下:
x
l
+
1
=
x
0
x
l
T
W
l
+
b
l
+
x
l
\boldsymbol{x}_{l+1}=\boldsymbol{x}_{\mathbf{0}}\boldsymbol{x}_{l}^{\mathrm{T}}\boldsymbol{W}_{l}+\boldsymbol{b}_{l}+\boldsymbol{x}_{l}
xl+1=x0xlTWl+bl+xl
可以看到, 交叉层操作的二阶部分非常类似于PNN 模型中提到的外积操作, 在此基础上增加了外积操作的权重向量 w l \boldsymbol{w}_{l} wl, 以及原输入向量 x l \boldsymbol{x}_{l} xl 和偏置向量 b l ∘ b_{l \circ} bl∘ 交叉层的操作如图 3-16 所示

在每次交叉中,只增加了一个n维权重参数,而且每次都保留了输入的特征w,这样使得每次交叉的输入输出不会差异很明显。
5.5 Wide&Deep的评价
Wide&Deep无疑是成功的,至今仍有很强的影响力,后续的模型也很多在他的基础上进行改进,比如DeepFM,NFM之类。成功在于:
- 掌握了业务问题的本质特点,能够融合传统模型的记忆能力和深度模型的泛化能力的优势
- 模型结构简单,工程易于实现,加速了工业界的应用
6 FNN,DeepFM,NFM—— FM+深度学习
随着深度学习时代的到来,FM模型族也开始了与深度学习的结合,并诞生了一系列的深度FM模型。
6.1 FNN——FM的隐向量作为Embedding层初始化
Deep Learning over Multi-field Categorical Data (UCL 2016)
FNN的模型结构和DeepCrossing的结构很类似,主要是在Embedding层进行了改善,使用了FM的权重对embedding参数进行了初始化。在常规的embedding层中,初始化往往使用随机初始化,不包含任何先验知识。
而且,对于过于稀疏的数据进入embedding层,收敛速度极慢,以及embedding的参数可能占到整个模型的一半以上,庞大的参数求解使得整个模型的收敛很慢。所以引入FM得到参数作为embedding层的初始权重,这样通过引入先验知识,使得起点更接近于最优点,依次加快收敛的速度。
下图给出FNN的模型结构,以及FM的参数如何运用到embedding层的初始权重。

可以看到的是,对于FM的参数主要分为三部分,分别是常数偏置
w
0
w_0
w0,一阶参数
w
i
w_i
wi,二阶参数
v
i
v_i
vi.
需要说明的是,在FM中,并没有对特征域进行区分,而在FNN中,不同的特征域对应不同的embedding层,而且每个特征域embedding维度都和FM的隐变量维度保持一致
6.2 DeepFM——用FM代替Wide部分
DeepFM: a factorization-machine based neural network for CTR prediction
FNN将FM的参数作为embedding层的初始权重,而没有网络结构进行改变,在2017年,华为和哈工大联合提出了DeepFM模型,将FM和Wide&Deep模型相结合。提出了以下的模型结构:

DeepFM也可可以看作是Wide&Deep模型的改进,主要是通过FM替代Wide模型,正如同Deep&Cross的改进一样,只不过是Deep&Cross是采用cross层代替了Wide,以此实现特征得交叉,增强特征得表达能力。
6.3 NFM——FM的神经网络尝试
Neural Factorization Machines for Sparse Predictive Analytics (NUS 2017)
在FM,FFM模型中,我们注意到其一个很大的缺点就是只能进行二阶特征组合,对于三阶以上交叉无法工程上实现,这就限制了FM的表达能力。
2017年,新加坡国立大学NUS提出了将FM改造为神经网络的表达形式,提出了NFM模型。
1 NFM模型结构
主要思路就是采用一个表达能力更强的函数替代FM模型中的二阶隐变量内积部分:
y ^ F M ( x ) = w 0 + ∑ i = 1 N w i x i + ∑ i = 1 N ∑ j = i + 1 N v i T v j ⋅ x i x j \hat{y}_{\mathrm{FM}}(x)=w_{0}+\sum_{i=1}^{N} w_{i} x_{i}+\sum_{i=1}^{N} \sum_{j=i+1}^{N} \boldsymbol{v}_{i}^{\mathrm{T}} \boldsymbol{v}_{j} \cdot x_{i} x_{j} y^FM(x)=w0+i=1∑Nwixi+i=1∑Nj=i+1∑NviTvj⋅xixj
y ^ N F M ( x ) = w 0 + ∑ i = 1 N w i x i + f ( x ) \hat{y}_{NFM}(x)=w_{0}+\sum_{i=1}^{N} w_{i} x_{i}+f(x) y^NFM(x)=w0+i=1∑Nwixi+f(x)
在深度学习时代,神经网络理论上可以拟合成一个表达能力任意强的函数,所以对于右侧的f(x)可以使用一个神经网络进行求解,如下:
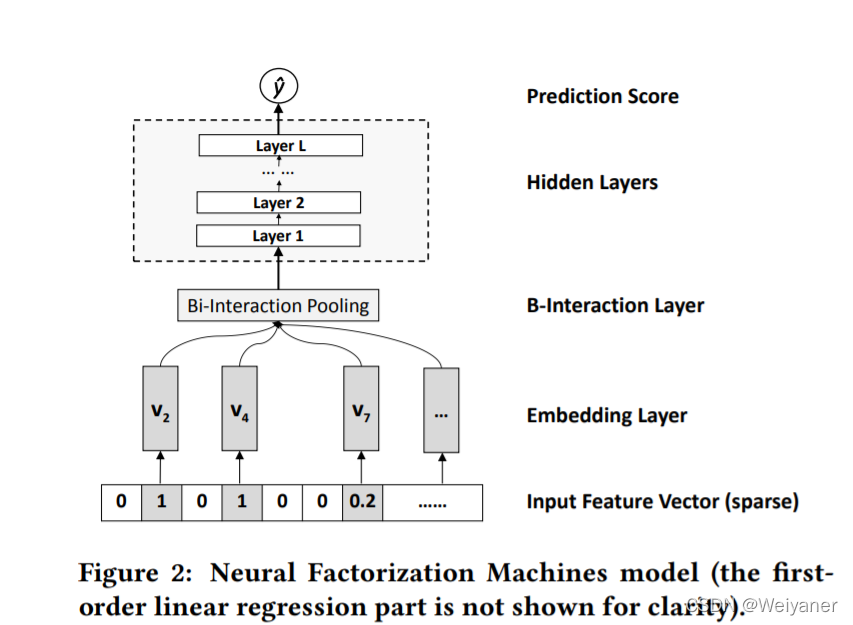 NFM的模型结构很明显,在Embedding层和隐藏层之间加入一个特征交叉层(B-Interaction Layer),假设V_x是所有embedding集合,特征交叉的操作为:
NFM的模型结构很明显,在Embedding层和隐藏层之间加入一个特征交叉层(B-Interaction Layer),假设V_x是所有embedding集合,特征交叉的操作为:
f
B
I
(
V
x
)
=
∑
i
=
1
n
∑
j
=
i
+
1
n
(
x
i
v
i
)
⊙
(
x
j
v
j
)
f_{\mathrm{BI}}\left(V_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n}\left(x_{i} v_{i}\right) \odot\left(x_{j} v_{j}\right)
fBI(Vx)=i=1∑nj=i+1∑n(xivi)⊙(xjvj)
其中,
⊙
\odot
⊙是向量积,代表着向量对应位置的乘积,不改变其维度。
通过向量积并求和之后,就得到了池化层的输出向量,接入多层全连接神经网络,最后进行输出预测得分。
2 另一个视角解读——Wide&Deep的Deep改进
如果将NFM从Wide&Deep的角度理解,可以看作是Deep部分的改进,加入了特征交叉池化层,加强了特征交叉的能力。
6.4 基于FM和深度学习的模型评价
本节介绍了FM与深度学习结合的三个主要模型,FNN,DeepFM,NFM。三者的特点都是在多层神经网络的基础上加入特征交叉操作,以此增加模型的表达能力。
跟随着特征自动化的路线,从PNN,经历了Wide&Deep,Deep&Cross,FNN,DeepFM,NFM等模型,进行了大量的特征互操作思路。但是特征工程的思路走到这里(2017年)几乎已经穷尽了,模型进一步提升的空间并不大,这也是这类模型的局限所在。
此后,更多的开始探索结构上的突破,诸如注意力模型,序列模型,强化学习等等。
上一篇:推荐系统(5)——推荐算法2(POLY2-FM-FFM-GBDT-MLR)
下一篇: