文章目录
- 1 ACF,DIN——注意力机制在推荐上的应用
- 1.1 AFM——NFM的交叉特征+Attention得分
- 1.2 DIN——淘系广告商品推荐的业务角度
- 1.3 注意力机制对于推荐系统的启发
- 2 DIEN——序列模型在推荐上的应用
- 2.1 为什么时序信息对于推荐是重要的?
- 2.2 DIEN的模型架构
- 1 兴趣抽取层——GRU
- 2 兴趣进化层——AUGRU注意力机制的体现
- 2.3 序列模型对于推荐系统的启发
- 3 DRN——强化学习在推荐上的应用
- 3.1 强化学习(Reinforcement Learning)经典过程
- 3.2 DRN框架
- 3.3 DRN的学习过程
- 3.4 竞争梯度下降算法
- 3.5 RL对于推荐系统的启发
在上文中,总结了深度学习时代以来的推荐算法发展,主要集中于特征工程上的突破,在尝试了各类型的特征交叉方法之后,似于特征工程对于模型的提升已经到了一个瓶颈期,所以更多的开始寻求结构上的突破,将人工智能其他领域成熟的模型结构引入推荐系统领域中,诸如“注意力机制”,序列模型,强化学习等等。
1 ACF,DIN——注意力机制在推荐上的应用
注意力机制在NLP和语音识别上的成功使得研究者开始考虑其在推荐系统上面的表现。2017年开始,浙大和阿里分别提出了AFM和DIN(2018)模型,作为业界的代表模型。
1.1 AFM——NFM的交叉特征+Attention得分
Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks (ZJU 2017)
AFM可以看作是在NFM的基础上完善的,上节我们说到NFM时,其特点在于对于特征进行了元素积交叉,再进行SUM pooling的操作。一视同仁对待左右交叉特征,没有考虑特征对结果的影响程度。
注意力机制的作用就在此处,他基于假设:不同交叉特征对于结果的影响程度不同。事实也常常如此,比如预测是否购买键盘的场景中,<sex = female & 购买过鼠标>的重要程度就大于<sex = female & age =30>。基于此,注意力机制通过给每个交叉特征加权来实现。
 在上方图可以看到,首先特征进行交叉,这里依然采用的NFM的元素积:
在上方图可以看到,首先特征进行交叉,这里依然采用的NFM的元素积:
f
P
I
(
ε
)
=
{
(
v
i
⊙
v
j
)
x
i
x
j
}
(
i
,
j
)
∈
R
x
f_{\mathrm{PI}}(\varepsilon)=\left\{\left(v_{i} \odot v_{j}\right) x_{i} x_{j}\right\}_{(i, j) \in \mathcal{R}_{x}}
fPI(ε)={(vi⊙vj)xixj}(i,j)∈Rx
通过注意力得分后,池化过程为:
f
Att
(
f
P
I
(
ε
)
)
=
∑
(
i
,
j
)
∈
R
x
a
i
j
(
v
i
⊙
v
j
)
x
i
x
j
f_{\text {Att }}\left(f_{\mathrm{PI}}(\varepsilon)\right)=\sum_{(i, j) \in \mathcal{R}_{\boldsymbol{x}}} a_{i j}\left(v_{i} \odot v_{j}\right) x_{i} x_{j}
fAtt (fPI(ε))=(i,j)∈Rx∑aij(vi⊙vj)xixj
对于交叉特征权重a_ij,最简单就是通过一个参数表示,为了防止交叉特征数据稀疏的问题带来权重难以收敛,AFM在Pair_wise Layer和池化层之间使用了Attention Layer来表示注意力得分。
$ a i j = ′ h T ReLU ( W ( v i ⊙ v j ) x i x j + b ) a i j = exp ( a i j ′ ) ∑ ( i , j ) ∈ R x exp ( a i j ′ ) \begin{array}{c}a_{i j=}^{\prime} \boldsymbol{h}^{\mathrm{T}} \operatorname{ReLU}\left(\boldsymbol{W}\left(\boldsymbol{v}_{i} \odot \boldsymbol{v}_{j}\right) x_{i} x_{j}+\boldsymbol{b}\right) \\a_{i j}=\frac{\exp \left(a_{i j}^{\prime}\right)}{\sum_{(i, j) \in \mathcal{R}_{x}} \exp \left(a_{i j}^{\prime}\right)}\end{array} aij=′hTReLU(W(vi⊙vj)xixj+b)aij=∑(i,j)∈Rxexp(aij′)exp(aij′)
其中要学习的模型参数就是特征交叉层到注意力网络全连接层的权重矩阵 W W W, 偏置向量 b b b, 以及全连接层到 softmax 输出层的权重向量 h h h 。
注意力网络将与 整个模型一起参与梯度反向传播的学习过程, 得到最终的权重参数。 A F M \mathrm{AFM} AFM 是研究人员从改进模型结构的角度出发进行的一次有益尝试。它与具 体的应用场景无关。但阿里巴巴在其深度学习推荐模型中引人注意力机制, 则 是一次基于业务观察的模型改进, 下面介绍阿里巴巴在业界非常知名的推荐模型一 D I N DIN DIN
1.2 DIN——淘系广告商品推荐的业务角度
Deep Interest Network for Click-Through Rate Prediction (Alibaba 2018)
在注意力机制前的推荐模型中,用户的所有不同兴趣(特征)压缩到同一个向量中,实际上,因为只有用户的部分兴趣会影响他/她的行为(点击或不点击)。例如,在上周的购物清单上,女性游泳者点击“推荐护目镜”时,大部分是因为购买了泳衣,而不是鞋子。基于此,该模型通过考虑给定候选广告的历史行为相关性,自适应地计算用户兴趣的表示向量。
相比较学术风格的深度模型,DIN明显更具有工业风,应用场景时Aalibaba的电商计算广告业务。预测用户是否点击广告时,模型的输入分为两大部分,分别是用户的特征组(过去点击过的店铺id和商品id)和广告特征组(广告的店铺id和商品id)。模型如下:

在Base模型中,用户特征和商品特征直接参与到sum池化层,之前没有任何交互。然后进行下一步训练。说明用户组的商品和广告组的商品没有进行关联。
在Deep模型中,通过将两个组的商品进行关联,给不同特征施加注意力得分也不同,注意力得分的计算理应也和广告的商品特征有关。
V
u
=
f
(
V
a
)
=
∑
i
=
1
N
w
i
⋅
V
i
=
∑
i
=
1
N
g
(
V
i
,
V
a
)
⋅
V
i
\boldsymbol{V}_{\mathrm{u}}=f\left(\boldsymbol{V}_{\mathrm{a}}\right)=\sum_{i=1}^{N} w_{i} \cdot \boldsymbol{V}_{i}=\sum_{i=1}^{N} g\left(\boldsymbol{V}_{i}, \boldsymbol{V}_{\mathrm{a}}\right) \cdot \boldsymbol{V}_{i}
Vu=f(Va)=i=1∑Nwi⋅Vi=i=1∑Ng(Vi,Va)⋅Vi
其中,
V
u
V_{\mathrm{u}}
Vu 是用户的 Embedding 向量,
V
a
V_{\mathrm{a}}
Va 是候选广告商品的 Embedding 向量,
V
i
V_{i}
Vi 是用户
u
\mathrm{u}
u 的第
i
i
i 次行为的 Embedding 向量。因为加人了注意力机制, 所以
V
u
\boldsymbol{V}_{\mathrm{u}}
Vu 从过去
V
i
\boldsymbol{V}_{i}
Vi 的加和变成了
V
i
\boldsymbol{V}_{i}
Vi 的加权和,
V
i
\boldsymbol{V}_{i}
Vi 的权 重
w
i
w_{i}
wi 就由
V
i
\boldsymbol{V}_{i}
Vi 与
V
a
\boldsymbol{V}_{\mathrm{a}}
Va 的关系决定, 也就是式中的
g
(
V
i
,
V
a
)
g\left(\boldsymbol{V}_{i}, \boldsymbol{V}_{\mathrm{a}}\right)
g(Vi,Va), 即 “注意力得分”。
注意力得分也是通过一个神经网络训练得到的,如模型结构右上角的结构,对于两个Embedding输入向量,经过元素减操作,在和原先的Embedding向量进行拼接输入全连接层,最后输出即得到注意力得分。
DIN模型与AFM模型比较,是一次基于业务的改进深度网络的尝试,很不错的工作。
1.3 注意力机制对于推荐系统的启发
在数学形式上,注意力的加入仅仅是将原先的交叉特征平均操作或者sum操作变成了平均加权或者加权求和操作,但是这一机制对于推荐系统的启发确是重要的。注意力得分的引入使得推荐系统具备了人思考过程中的注意力特点,更加接近用户的角度出发,从而提升推荐的效果。
2 DIEN——序列模型在推荐上的应用
Deep Interest Evolution Network for Click-Through Rate Prediction (Alibaba 2019)
阿里在DIN之后又推出了DIEN,主要是通过序列模型模拟用户的兴趣进化过程。
2.1 为什么时序信息对于推荐是重要的?
用户的特定行为是一个时间序列,这个时序信息对于推荐系统无疑是重要的,在DIEN之前的模型没有一个运用时序信息来进行推荐。即是是AFM和DIN也只是对历史行为施加注意力得分,和时间,序列都没有关系。
一个典型的电商现象来说明时序信息的重要性。对于一个综合用户,其兴趣迁移的很快,一周前他挑选球鞋,那么过去一周客户的兴趣主要集中在球鞋上面,但是购买完成后,他的兴趣可能变成其他的机械键盘,不再是球鞋了。
序列信息的重要性在于:
- 加强了最近行为对下次行为的预测,比如购买机械键盘的概率将远远大于球鞋类似的。
- 序列模型可以学习到购买趋势。通过建立球鞋到键盘的转移概率,如果该统计是全局的,那么下次再购买完球鞋推荐机械键盘就不错。
从业务的角度上,短期的购买行为更能决定下一次的购买预测。
2.2 DIEN的模型架构
阿里再DIN基础上进行改进,模型依然是输入层+Embedding+连接层+多层FC+输出层的架构。下图彩色部分认为是用户的兴趣进化网络,对用户兴趣进行embedding建模,输出一个用户兴趣向量
h
′
(
T
)
h'(T)
h′(T),模型主要围绕着如何构建这个用户兴趣进化网络。

彩色部分可以看到,主要包括三层
- 用户行为层(Behavior Layer):将原始的id类行为序列转化为Embedding向量序列。与普通的Embedding层一致。
- 兴趣抽取层(Interest Extractor Layer):模拟用户的兴趣迁移,抽取兴趣
- 兴趣进化层(Interest Evolving Layer):在兴趣抽取层得到的兴趣特征加以注意力机制,模拟与当前目标广告的兴趣迁移程度。
1 兴趣抽取层——GRU
在兴趣抽取层,采用了GRU(gate Recurrent Unit)网络,相比传统的RNN模型,解决了梯度消失的问题,与LSTM(同样解决了梯度消失)相比,GRU的参数更少,训练收敛速度更快。
单个 GRU 单元的具体形式由系列下式定义:
u
t
=
σ
(
W
u
i
t
+
U
u
h
t
−
1
+
b
u
)
r
t
=
σ
(
W
r
i
t
+
U
r
h
t
−
1
+
b
r
)
h
t
~
=
tanh
(
W
h
i
t
+
r
t
∘
U
h
h
t
−
1
+
b
h
)
h
t
=
(
1
−
u
t
)
∘
h
t
−
1
+
u
t
∘
h
~
t
\begin{array}{c}\boldsymbol{u}_{t}=\sigma\left(\boldsymbol{W}^{u} \boldsymbol{i}_{t}+\boldsymbol{U}^{u} \boldsymbol{h}_{t-1}+\boldsymbol{b}^{u}\right) \\\boldsymbol{r}_{t}=\sigma\left(\boldsymbol{W}^{r} \boldsymbol{i}_{t}+\boldsymbol{U}^{r} \boldsymbol{h}_{t-1}+\boldsymbol{b}^{r}\right) \\\widetilde{\boldsymbol{h}_{t}}=\tanh \left(\boldsymbol{W}^{h} \boldsymbol{i}_{t}+\boldsymbol{r}_{t} \circ \boldsymbol{U}^{h} \boldsymbol{h}_{t-1}+\boldsymbol{b}^{h}\right) \\\boldsymbol{h}_{t}=\left(1-\boldsymbol{u}_{t}\right) \circ \boldsymbol{h}_{t-1}+\boldsymbol{u}_{t} \circ \widetilde{\boldsymbol{h}}_{t}\end{array}
ut=σ(Wuit+Uuht−1+bu)rt=σ(Writ+Urht−1+br)ht
=tanh(Whit+rt∘Uhht−1+bh)ht=(1−ut)∘ht−1+ut∘h
t
其中, σ \sigma σ 是 Sigmoid 激活函数, ∘ \circ ∘ 是元素积操作, W u , W r , W h , U z , U r , U h \boldsymbol{W}^{u}, \boldsymbol{W}^{r}, \boldsymbol{W}^{h}, \boldsymbol{U}^{z}, \boldsymbol{U}^{r}, \boldsymbol{U}^{h} Wu,Wr,Wh,Uz,Ur,Uh 是 6 组需要学习的参数矩阵, i t i_{t} it 是输人状态向量, 也就是行为序列层的各行为 Embedding 向量 b ( t ) , h t \boldsymbol{b}(t), \boldsymbol{h}_{t} b(t),ht 是 GRU 网络中第 t t t 个隐状态向量。
经过由 GRU 组成的兴趣抽取层后, 用户的行为向量 b ( t ) \boldsymbol{b}(t) b(t) 被进一步抽象化, 形成了兴趣状态向量 h ( t ) \boldsymbol{h}(t) h(t) 。理论上, 在兴趣状态向量序列的基础上, GRU 网络已 经可以做出下一个兴趣状态向量的预测, 但 DIEN 却进一步设置了兴趣进化层, 这是为什么呢?
2 兴趣进化层——AUGRU注意力机制的体现
兴趣进化层就是针对上一层提取的兴趣特征加以之注意力,以此表示对不同兴趣的重要程度,这是在兴趣抽取层中没有实现的。注意力得分的生成和DIN一样,都是通过和广告特征向量进行关联求解。在GRU的基础上,增加的注意力机制,表现为:
u
~
t
′
=
a
t
⋅
u
t
′
h
t
′
=
(
1
−
u
~
t
′
)
∘
h
t
−
1
′
+
u
~
t
′
∘
h
~
t
′
\begin{array}{l}\tilde{\boldsymbol{u}}_{t}^{\prime}=a_{t} \cdot \boldsymbol{u}_{t}^{\prime} \\\boldsymbol{h}_{t}^{\prime}=\left(1-\widetilde{\boldsymbol{u}}_{t}^{\prime}\right) \circ \boldsymbol{h}_{t-1}^{\prime}+\widetilde{\boldsymbol{u}}_{t}^{\prime} \circ \widetilde{\boldsymbol{h}}_{t}^{\prime}\end{array}
u~t′=at⋅ut′ht′=(1−u
t′)∘ht−1′+u
t′∘h
t′
可以看出 AUGRU 在原始的 u t ′ \boldsymbol{u}_{t}^{\prime} ut′ [ 原始更新门向量, 如(式 3-17)中的 u t u_{t} ut ] 基础上加人了注意力得分 a t a_{t} at, 注意力得分的生成方式与 DIN 模型 中注意力激活单元的基本一致
2.3 序列模型对于推荐系统的启发
实际上,不仅阿里使用序列模型对下次用户的购买进行预测,Youtube,Nexflix等视频流媒体公司也成功的使用序列模型进行推荐。
缺陷:
- 需要更高的模型复杂度,给训练和线上推断过程中的串行计算带来了难度,使其推断的延迟较大。
3 DRN——强化学习在推荐上的应用
DRN- A Deep Reinforcement Learning Framework for News Recommendation (MSRA 2018)
强化学习是最近几年机器学习领域很火的话题,起初运用于多智能体领域,在智能体学习过程中,感知外界变化,收集外部反馈,在改进自身状态,并对下一步自身状态进行决策。通过持续的循环(行动-反馈-状态更新)来实现目标。
在推荐系统中,也可以看作是一个行动-反馈-状态更新的循环,所以强化学习理论上也是可以应用于推荐系统的。2018年,宾夕法尼亚州立大学和微软亚研院MSRA提出了DRN,看作是强化学习在推荐系统上的应用尝试。
3.1 强化学习(Reinforcement Learning)经典过程
下图就是多智能体强化学习的经典过程。在推荐系统中,强化学习扮演的角色是这样的:

- 智能体Agent:推荐系统本身,包括推荐模型,策略,数据存储
- 环境:新闻网站,用户在环境中接收推荐系统的结果做出反馈
- 行动:推荐系统对新闻排序之后推送用户的动作
- 反馈:用户接受行动之后,做出正向和负向的反馈。click or not click等等
- 状态:已接受到所有的行动和反馈,用户的特征向量表示。在机器学习可以看作是可用于训练的集合。
与深度模型相比,强化学习推荐系统的优势就是在于可以在线学习,不断利用更新的知识完善自己,及时做出反应和调整。
3.2 DRN框架
主要就是一句Q强化学习进行的,形成了Deep Q-Network,DQN。其中Q是quality的意思,对行动质量进行评估,进而得到行动的有效得分,以此进行行动决策。
网络结构如下:

状态向量:用户特征+环境特征
行动向量:用户-新闻特征+新闻特征
状态特征经过左侧的多层神经网络得到一个分数,同时右侧对状态向量和行动向量得到一个分数,两个分数综合起来就是最终的质量分数。
3.3 DRN的学习过程
因为强化学习的在线更新才使得模型具有更好的实时性,其重点就在于学习过程:

从左到右,依次介绍:
- 离线部分:根据历史数据训练好DQN模型,作为初始化模型
- t1-t2部分:利用初始化模型进行短期发的推送,积累反馈数据
- 在t2时刻:利用前一时期的积累数据,对模型进行微调更新
- 在t4时刻:利用t1-t4时间段积累的反馈数据对模型进行主更新
- 重复2-4
3.4 竞争梯度下降算法
在主更新可以理解为使用历史数据重新训练模型,替换原来的model,那么t2时刻的模型微调怎么实现,这是一种在线训练方法——Dueling Bandit Gradient Descent Algorithm,竞争梯度下降法。
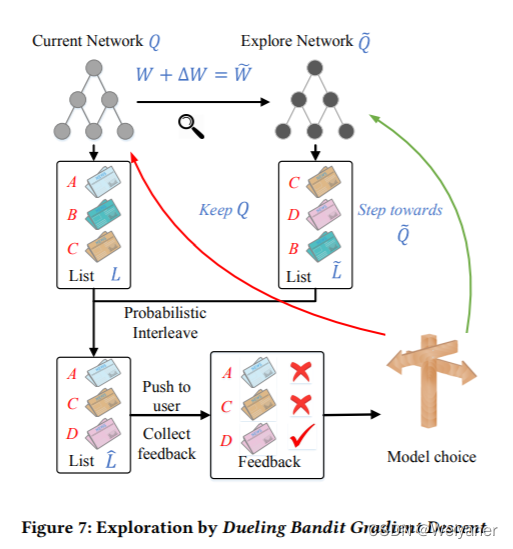
主要步骤:
- 对于已经训练好的模型
Q
Q
Q,其参数W施加一个随机扰动,得到另外一组参数,对应的模型成为探索网络
Q
′
Q'
Q′。扰动公式为:
Δ
W
=
α
⋅
rand
(
−
1
,
1
)
⋅
W
\Delta \mathrm{W}=\alpha \cdot \operatorname{rand}(-1,1) \cdot \mathrm{W}
ΔW=α⋅rand(−1,1)⋅W
其中, α \alpha α是一个探索因子,控制微调的幅度。 - 对于当前Q和 Q ′ Q' Q′分别生成一个推荐列表,通过InterLeaving方法合并为一个List,推送给用户。
- 实时收集用户反馈,两个网络哪个好就用哪个,实现微调模型。
3.5 RL对于推荐系统的启发
强化学习是继注意力机制,时序模型后再一次突破了深度推荐模型的思路,变静态为动态,提高了模型的实时性。
由此也引申了一个问题,究竟是打造一个完美的但是延迟高的模型还是轻巧简单但是实时性高的模型
个人认为,在质量和时效之间没有极端的好坏取舍,而是应该根据应用的业务场景不同,选择一个合适的模型。
到此为止,深度学习时代的推荐算法介绍完了,但是推荐算法的发展确实日新月异,越来越快,更重要的是要时刻保持热点,不要让自己掉出前沿方向的大队。
上一篇:推荐系统(6)——推荐算法3(深度学习时代来临:AutoRec,Deep Crossing,NeuralCF,PNN,Wide&Deep,FNN,DeepFM,NFM)






