文章目录
- 1 推荐系统为何需要多样性
- 2 多样性类型
- 3 多样性评价指标
- 4 如何改进多样性
- 召回阶段——多路融合
- 排序阶段——多特征建模
- 重排阶段
- 不同用户的多样性需求分析
推荐系统的多样性反应了一个推荐列表中内容不相似的程度。通过推荐多样性更高的内容,既能够给用户更多的机会去发现新内容,也能够让推荐系统更容易发现用户潜在的兴趣。
需要注意的是,精确性和多样性是一对Trade Off,提升多样性的代价往往以牺牲准确性为代价,因此如何平衡准确性和多样性是一个需要权衡的地方,或者从另一个角度讲如何在短期目标和长期目标间做平衡。
1 推荐系统为何需要多样性
在推荐系统中,一般主要关注于对用户的兴趣进行建模,推送其兴趣相似的items,这就导致了:
- 相似内容扎堆,影响用户体验,过于乏味
- 造成“信息茧房”,用户获取信息面过窄,信息为0.
- 兴趣宽泛或者表达不明确的用户体验差
多样性一般不作为建模目标,但是通过实践也证明了多样性的提升可以帮助提升时长、点击、用户长期留存等核心业务指标,这些通常需要A/B实验来确定多样性策略的优劣。
2 多样性类型
推荐多样性类型包括个体多样性、总体多样性、时序多样性。

-
个体多样性
个体多样性从单个用户的视角衡量推荐的多样性,考察系统能够找到用户喜欢的冷门项目的能力。
个体水平的多样性反映了推荐列表包含的主题数量以及推荐项目在不同主题上分布的均衡性。 -
系统多样性
系统多样性主要强调针对不同用户的推荐应尽可能的不同。也就是所谓的"千人千面"。低系统级别的多样性意味着总是向所有用户推荐热门项目,而忽略长尾项目。因此,系统多样性也被称作长尾推荐。 -
时序多样性
时序多样性是指用户兴趣的动态进化或者用户情景的时变,即与过去的推荐相比,新的推荐体现出的多样性。
评价一个推荐系统的多样性可以从以上三个维度考量。
3 多样性评价指标
1、ILS(intra-list similarity)
ILS主要是针对单个用户,一般来说ILS值越大,单个用户推荐列表多样性越差。ILS主要是针对单个用户,一般来说ILS值越大,单个用户推荐列表多样性越差。
ILS
(
R
)
=
2
k
(
k
−
1
)
∑
i
∈
j
≠
i
∈
R
∑
R
Sim
(
i
,
i
)
\operatorname{ILS}(R)=\frac{2}{k(k-1)} \sum_{i \in j \neq i \in R} \sum_{R} \operatorname{Sim}(i, i)
ILS(R)=k(k−1)2i∈j=i∈R∑R∑Sim(i,i)
其中,
i
i
i 和
j
j
j 为Item,
k
k
k 为推荐列表长度,
Sim
(
.
)
\operatorname{Sim}(.)
Sim(.) 为相似性度量。
2、 海明距离(Hamming distance)
H
i
j
=
1
−
Q
i
j
L
H_{i j}=1-\frac{Q_{i j}}{L}
Hij=1−LQij
其中,
L
L
L 为推荐列表长度,
Q
i
j
Q_{i j}
Qij 为系统推荐给用户
i
i
i 和
j
j
j 两个推荐列表中相同Item的数量。
H
i
j
H_{i j}
Hij 衡量了不同用户间的推荐结果的差异性,其值越大说明不同用户间的多样性程度越高。
3、SSD (self-system diversity)
SSD指推荐列表中没有包含在以前的推荐列表中的比例,主要考崇推荐结果的时序多样性。
SSD
(
R
∣
u
)
=
∣
R
/
R
t
−
1
∣
∣
R
∣
\operatorname{SSD}(R \mid u)=\frac{\left|R / R_{t-1}\right|}{|R|}
SSD(R∣u)=∣R∣∣R/Rt−1∣
其中,
R
t
−
1
R_{t-1}
Rt−1 是
R
R
R 的上一次推荐,
R
/
R
t
−
1
=
{
x
∈
R
∣
x
∉
R
t
−
1
}
R / R_{t-1}=\left\{x \in R \mid x \notin R_{t-1}\right\}
R/Rt−1={x∈R∣x∈/Rt−1} 。SSD值越小,推荐列表的时序多样性越好。
4、覆盖率 (coverage)
覆盖率是推荐给用户的Item占所有Item的比例,用来衡量对长尾Item的推茯能力。
5、K 次重复率
在一次推荐请求中,同一类别的Item连续出现
K
K
K 次的比率。
6、Hellinger距离
通过计算生成的topK结果的多样性分布和理想的多样性分布之间的Hellinger距离,来衡量top K 结果多样性的好坏。
H
(
P
,
Q
)
=
1
2
∑
i
=
1
k
(
p
i
−
q
i
)
2
.
H(P, Q)=\frac{1}{\sqrt{2}} \sqrt{\sum_{i=1}^{k}\left(\sqrt{p_{i}}-\sqrt{q_{i}}\right)^{2}} .
H(P,Q)=21i=1∑k(pi−qi)2.
其中,
P
=
(
p
1
,
p
2
,
…
,
p
k
)
P=\left(p_{1}, p_{2}, \ldots, p_{k}\right)
P=(p1,p2,…,pk) 和
Q
=
(
q
1
,
q
2
,
…
,
q
k
)
Q=\left(q_{1}, q_{2}, \ldots, q_{k}\right)
Q=(q1,q2,…,qk) 为离散概率分布。
4 如何改进多样性
一般在推荐架构中,主要分为三部分,分别是召回,排序和业务策略。其中排序又分为粗排,精排和重排。

召回阶段——多路融合
只有第一步的召回存在多样性的item,后续的推荐结果中才有可能提升多样性结果。
因此解决推荐系统的多样性问题,首先需要考虑的是召回阶段的多样性。实践中通常使用多路召回保证更多样的内容可以进入后续阶段,工程上可以采用多线程并发召回。

排序阶段——多特征建模
排序阶段可以融入不同维度的特征进行建模,加入User、Item、环境特征,达到在不同的维度的多样性,一般来讲特征越丰富个性化越强同时多样性越强。
重排阶段

重排序的本质是最大化list-wise的打分函数
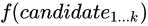
在相关性和多样性间取得平衡,从运筹学角度来讲是一个典型的组合优化问题,一般也是NP-Hard(不能在有限时间内得到精确最优解)。
多样性优化策略,工业界的代表性方法有:MRR、DPP、PRM等。
参考:https://zhuanlan.zhihu.com/p/264652162
不同用户的多样性需求分析
参考:https://blog.csdn.net/qq_28298991/article/details/80697205
论断:
不同活跃度的用户对推荐结果多样性的需求是不同的
活跃度越大的用户其多样性偏好也应该越大。
对低活跃度用户,他们仅仅交互了少量的物品,其行为数据不足以刻画他们的兴趣偏好,这是应该关注提高他们的推荐准确率,为他们推荐一些热门的物品而不是盲目的提高多样性,在保证一定的准确率后,用户产生更多的交互行为以后,再提高其推荐列表的多样性。
所以,作者提出的多样性问题的解决方式就是,为了平衡推荐结果的多样性和准确率,对低活跃度用户,优先考虑准确率,忽略其推荐多样性,对高活跃度用户,重视推荐列表的多样性水平,可以允许推荐结果的准确率有一定的损失。







