DeepFM
DeepFM模型是2017年由哈工大与华为联合提出的模型,是对Wide&Deep模型的改进。与DCN不同的是,DeepFM模型是将Wide部分替换为了FM模型,增强了模型的低阶特征交互的能力。关于低阶特征交互,文章的Introduction中也提到了其重要性,例如:
1、用户经常在饭点下载送餐APP,故存在一个2阶交互:app种类与时间戳;
2、青少年喜欢射击游戏和RPG游戏,存在一个3阶交互:app种类、用户性别和年龄;
用户背后的特征交互非常的复杂,低阶和高阶的特征交互都是很重要的,这也证明了Wide&Deep这种模型架构的有效性。DeepFM是一种端到端的模型,强调了包括低阶和高阶的特征交互接下来直接对DeepFM模型架构进行介绍,并与其他之前提到过的模型进行简单的对比。
模型结构
DeepFM的模型结构非常简单,由Wide部分与Deep部分共同组成,如下图所示:
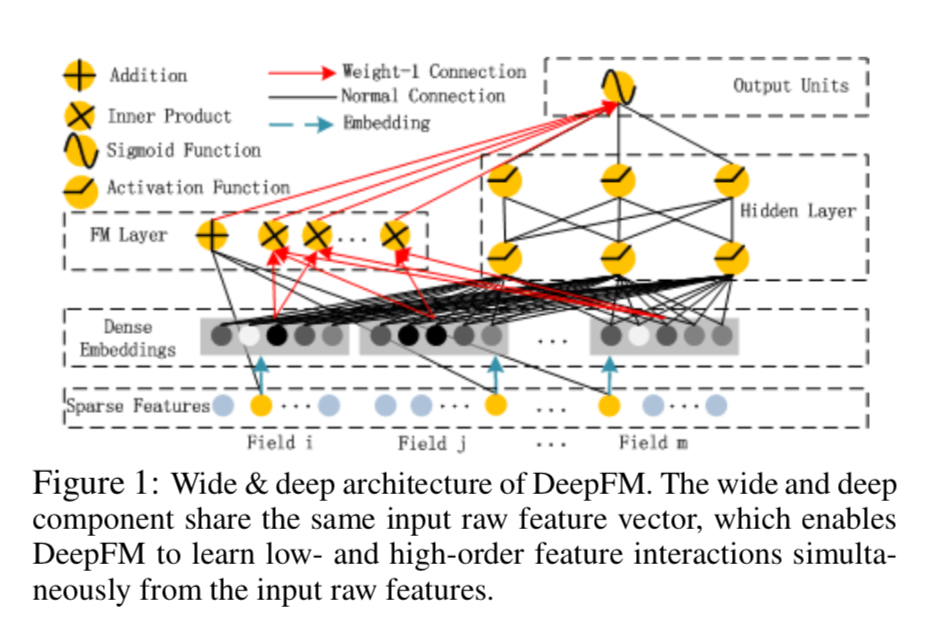
在论文中模型的目标是共同学习低阶和高阶特征交互,应用场景依旧是CTR预估,因此是一个二分类任务( y = 1 y=1 y=1表示用户点击物品, y = 0 y=0 y=0则表示用户未点击物品)
Input与Embedding层
关于输入,包括离散的分类特征域(如性别、地区等)和连续的数值特征域(如年龄等)。分类特征域一般通过one-hot或者multi-hot(如用户的浏览历史)进行处理后作为输入特征;数值特征域可以直接作为输入特征,也可以进行离散化进行one-hot编码后作为输入特征。
对于每一个特征域,需要单独的进行Embedding操作,因为每个特征域几乎没有任何的关联,如性别和地区。而数值特征无需进行Embedding。
Embedding结构如下:
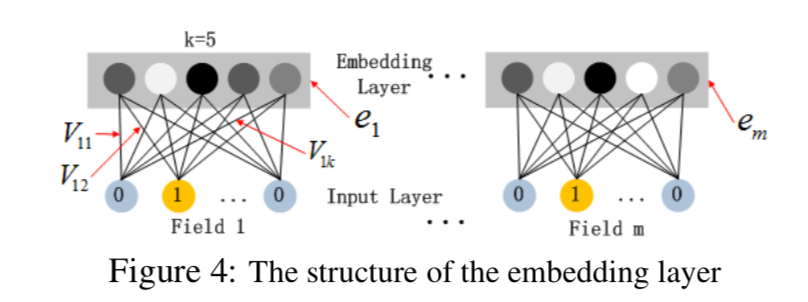
文章中指出每个特征域使用的Embedding维度 k k k都是相同的。
【注】与Wide&Deep不同的是,DeepFM中的Wide部分与Deep部分共享了输入特征,即Embedding向量。
Wide部分—FM
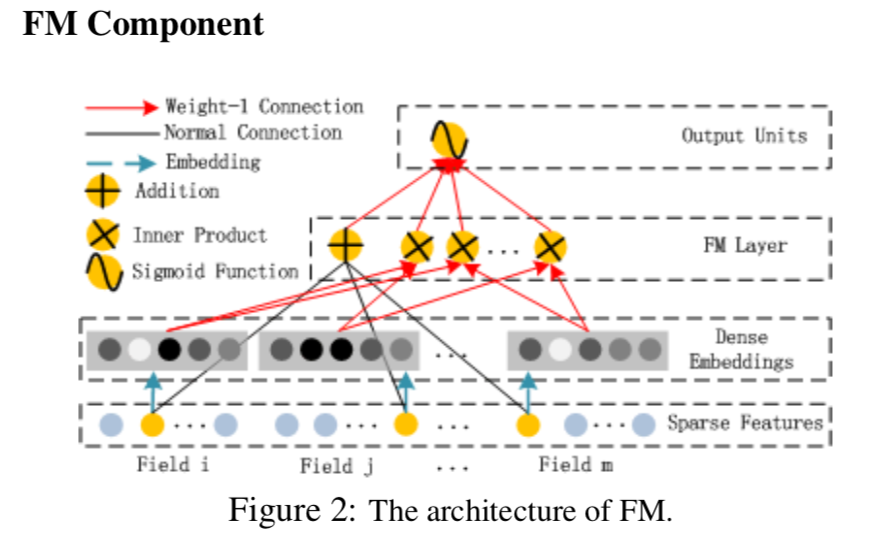
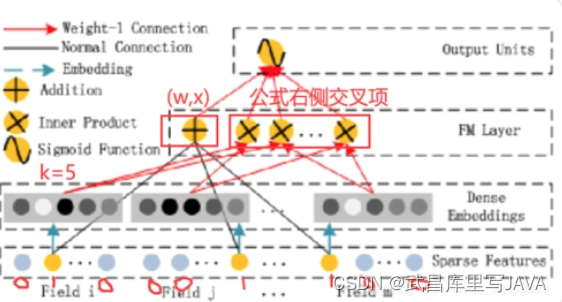
FM模型[^4]是2010年Rendle提出的一个强大的非线性分类模型,除了特征间的线性(1阶)相互作用外,FM还将特征间的(2阶)相互作用作为各自特征潜向量的内积进行j建模。通过隐向量的引入使得FM模型更好的去处理数据稀疏行的问题,想具体了解的可以看一下原文。DeepFM模型的Wide部分就直接使用了FM,Embedding向量作为FM的输入。
y
F
M
=
⟨
w
,
x
⟩
+
∑
j
1
=
1
d
∑
j
2
=
j
1
+
1
d
⟨
V
i
,
V
j
⟩
x
j
1
⋅
x
j
2
y_{F M}=\langle w, x\rangle+\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}
yFM=⟨w,x⟩+j1=1∑dj2=j1+1∑d⟨Vi,Vj⟩xj1⋅xj2
其中
w
∈
R
d
w \in \mathbf{R}^d
w∈Rd,
⟨
w
,
x
⟩
\langle w, x\rangle
⟨w,x⟩表示1阶特征,
V
i
∈
R
k
V_i \in \mathbf{R}^k
Vi∈Rk表示第
i
i
i个隐向量,
k
k
k表示隐向量的维度,
∑
j
1
=
1
d
∑
j
2
=
j
1
+
1
d
⟨
V
i
,
V
j
⟩
x
j
1
⋅
x
j
2
\displaystyle\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}
j1=1∑dj2=j1+1∑d⟨Vi,Vj⟩xj1⋅xj2表示2阶特征。
具体的对于2阶特征,FM论文中有下述计算(采取原文的描述形式),为线性复杂复杂度
O
(
k
n
)
O(kn)
O(kn):
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
=
1
2
∑
i
=
1
n
∑
j
=
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
−
1
2
∑
i
=
1
n
⟨
v
i
,
v
i
⟩
x
i
x
i
=
1
2
(
∑
i
=
1
n
∑
j
=
1
n
∑
f
=
1
k
v
i
,
f
v
j
,
f
x
i
x
j
−
∑
i
=
1
n
∑
f
=
1
n
v
i
,
f
v
i
,
f
x
i
x
i
)
=
1
2
∑
f
=
1
k
(
(
∑
i
=
1
n
v
i
,
f
x
i
)
(
∑
j
=
1
n
v
j
,
f
x
j
)
−
∑
i
=
1
n
v
i
,
f
2
x
i
2
)
=
1
2
∑
f
=
1
k
(
(
∑
i
=
1
n
v
i
,
f
x
i
)
2
−
∑
i
=
1
n
v
i
,
f
2
x
i
2
)
\begin{aligned} & \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\=& \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}-\frac{1}{2} \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \\=& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{n} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\=& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \end{aligned}
====i=1∑nj=i+1∑n⟨vi,vj⟩xixj21i=1∑nj=1∑n⟨vi,vj⟩xixj−21i=1∑n⟨vi,vi⟩xixi21
i=1∑nj=1∑nf=1∑kvi,fvj,fxixj−i=1∑nf=1∑nvi,fvi,fxixi
21f=1∑k((i=1∑nvi,fxi)(j=1∑nvj,fxj)−i=1∑nvi,f2xi2)21f=1∑k
(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2
Deep部分
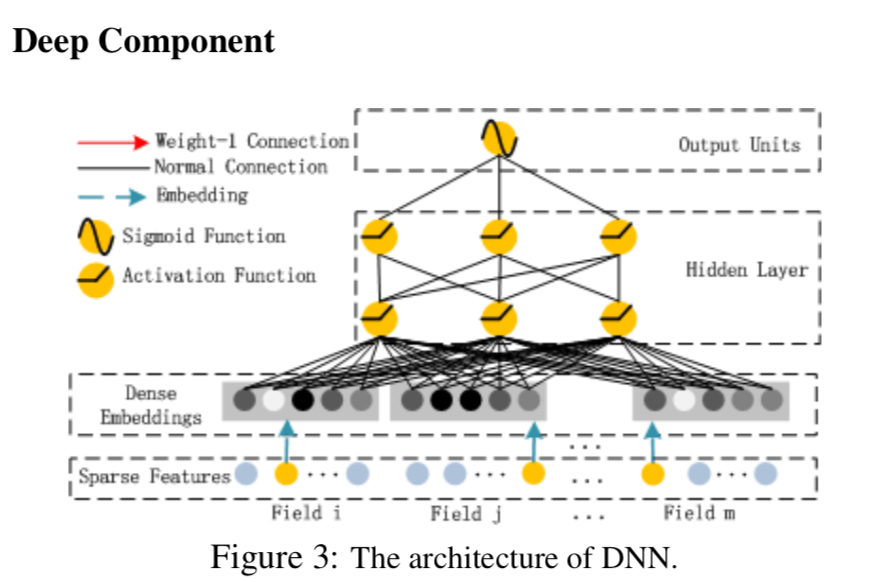
Deep部分是一个前向传播的神经网络,用来学习高阶特征交互。
Output层
FM层与Deep层的输出相拼接,最后通过一个逻辑回归返回最终的预测结果:
y
^
=
s
i
g
m
o
i
d
(
y
F
M
+
y
D
N
N
)
\hat y=sigmoid(y_{FM}+y_{DNN})
y^=sigmoid(yFM+yDNN)
面试相关
1、Wide&Deep与DeepFM的区别?
Wide&Deep模型,Wide部分采用人工特征+LR的形式,而DeepFM的Wide部分采用FM模型,包含了1阶特征与二阶特征的交叉,且是端到端的,无需人工的特征工程。
2、DeepFM的Wide部分与Deep部分分别是什么?Embedding内容是否共享
Wide:FM,Deep:DNN;
Embedding内容是共享的,在FM的应用是二阶特征交叉时的表征。