【如无特殊说明,本文所有图片均来源于网络】
IAB平台,使命和功能
IAB成立于1996年,总部位于纽约市。
作为美国的人工智能科技巨头社会媒体和营销专业平台公司,互动广告局(IAB- the Interactive Advertising Bureau)自1996年成立以来,先后为700多家媒体和营销会员企业赋能 - 为这些领先的媒体公司、品牌、代理商和负责销售、交付和优化数字广告营销活动公司和机构提供数字化营销平台服务和技术援助。IAB公司的使命是帮助平台上的企业快速高效转向数字化营销并建试图在行业之间推动数字化营销的标准并普及推广。
IAB使媒体和营销行业能够在数字经济中蓬勃发展。针对互联网数字世界营销广告眼花缭乱,鱼目混珠的现状,互动广告局带头进行了批判性研究,同时也对品牌、代理商和更广泛的商业界进行了数字营销重要性的教育。 IAB组建了人工智能标准工作组(the AI standards working group),2019年12月他们发布了第一份报告《人工智能与市场营销中的应用》。随即2020年,IAB联合IBM的WATSON广告和尼尔森公司(Nielsen)决定致力于研发与市场营销相关的人工智能技术、最佳行业实践、(推广)人工智能的案例和(规范)营销类人工智能技术条款术语来帮助营销负责人迅速转向数字化营销市场,拥抱人工智能和机器学习技术。 IAB与IAB技术实验室合作,制定技术标准和解决方案。IAB致力于专业发展,提升整个行业员工的知识、技能、专业知识和多样性。贸易协会通过其在华盛顿特区的公共政策办公室的工作,为其成员进行宣传,并向立法者和政策制定者宣传互动广告业的价值。
IAB全球网络汇集了包括三个区域组织在内的45个IAB组织,以分享挑战,开发全球解决方案,并推动全球数字广告业。IAB分布在北美、南美、非洲、亚洲、亚太和欧洲。每个协会都是独立拥有和运营的,根据符合当地市场需求的章程运作。

第五篇:对应场景下的人工智能和机器学习技术 – 创意创新(creative)
一、作者介绍
Robert Redmond,人工智能广告产品设计主管,设计负责人,IBM Watson
本文推荐受众:
首选读者:技术人员
次级读者:市场营销公司高层和市场营销人员

sources: Innovator Insights: IBM Watson Advertising's Robert Redmond On The Quest To Tackle Bias In AI-Based Advertising

二、哪些人工智能和机器学习技术可以满足创意创新需求
常见与创意有关的人工智能和机器学习技术当前的动态创意优化(DCO)方法要求品牌为适当的消费者环境预先规划正确的信息,并且随着活动的成熟,几乎没有学习适应的空间。
预测和回归的机器学习模型正在重塑动态创意组装的前景,使品牌能够预测哪些元素最能与每一位观众产生共鸣。
三、预测和回归等技术的原理

预测性创意平台不断消耗“最后一英里”的消费者和上下文数据信号,以确定创意和复制元素的最佳组合,从而帮助推动最高的参与度和(最终)转化。这些模型侧重于了解消费者的哪些行为在多个变体中推动实现最佳KPI。这种学习在整个活动中不断使用,通过重新组合他们所接触的广告,努力使个人更接近预期结果,例如网站转换或购买。
当活动开始时,无监督算法从消费者驱动的特征中构建集群,然后选择对特定集群表现最好的创造性组合。在有足够的训练印象量之后,为每个创造性组合建立监督回归模型,并基于转换动作的概率进行校准。在整个活动过程中,模型会继续学习和完善方法,利用错过的与整体受众相关的机会,同时定义丰富的活动指标,为创造性和战略见解提供信息。
预测建模管道(Predictive modeling Pipeline)
1. 预测建模步骤
每一种预测建模方法都遵循一系列步骤来实现端到端的防傻系统。它可以概括为一个8步流水线,如下所述:
2. 了解业务目标
第一步是了解相关业务的目标和必要性。这包括有关客户、市场和客户商业模式的详细信息。使用这些细节,我们定义了一个特定的问题。
3. 定义模型目标
在这一步中,我们根据预测分析来指定和定义问题陈述,该问题陈述使用预测建模来解决。我们还决定了将用于测试模型有效性的不同指标。
4. 正式收集数据
现在已经定义了目标和问题陈述,我们继续收集相关数据并创建所需的数据集。
5. 准备数据
由于收集的数据是原始的和未处理的,我们需要对其进行准备和组织。这将使我们能够建立一个更好、更准确的预测模型。
6. 处理和隔离数据
然后需要对收集的数据进行统计处理,即必须将因变量和自变量分开。在将数据输入到模型之前,还必须执行所需的数据处理操作,如填充缺失值、处理数值和分类值等。
7. 选择型号
既然我们已经准备好了问题陈述和数据集,我们就可以继续选择模型了。这取决于我们正在执行的建模类型。例如,是否是回归、分类、预测等。
8. 培训和验证
这是预测建模过程中最重要的一步。在这里,使用处理后的数据集对所选模型进行训练,并在单独的验证数据集上进行验证。验证数据集是使用各种交叉验证技术创建的,如k折叠、分层k折叠等。
9. 优化和部署
通过在不同的测试和验证数据集上对训练后的模型进行测试,对其进行优化。模型的度量被最大化。然后,它被部署到生产中,在那里它提供真实世界数据的结果。
预测模型的类型

有各种建模算法和技术可以用于不同的用例。一些最重要的模型包括:
1. 分类模型
分类模型将数据样本分类为指定的不同类别。垃圾邮件检测和欺诈交易检测就是这一类的好例子。
2. 聚类模型
聚类模型是一种无监督的预测建模方法。它根据共享的特征或行为对数据样本进行分组。这有助于公司在与现有集群绘制时检测新数据样本的行为/类别。一个真实世界的例子是根据过去的数据模式预测贷款申请人的信贷风险。另一种是零售营销,营销人员可以使用共同的特征来分析一组客户的消费习惯和产品兴趣,从而更容易地进行目标广告。
3. 预测模型
预测模型使用数值的历史数据,即股票价格、商品价格、房地产价值趋势等,并根据过去数据的模式预测未来价值。其中一些应用程序可以根据过去的月度订单和供应链统计数据预测制造业的原材料。
4. 异常值模型
异常值模型通过识别外围数据点来工作。这有助于识别异常行为或异常。该模型的最佳应用之一是基于与过去的消费习惯和模式无关的事实来识别欺诈/异常交易。
常用流行的预测分析算法
预测建模中使用的算法通常基于机器学习(ML)或深度学习(DL)。两者都是具有不同应用的人工智能(AI)的子集。ML应用于结构化数据,如表格数据和数值数据集。DL使用神经网络,用于图像、音频、视频和文本等非结构化数据。
| NO | 预测模型 | 预测模型技术 |
| 1 | Regression 回归 | Linear regression, polynomial regression, and logistic regression. 线性回归、多项式回归和逻辑回归。 |
| 2 | Neural network 神经网络 | Multilayer perceptron (MLP), convolutional neural networks (CNN), recurrent neural networks (RNN), backpropagation, feedforward, autoencoder, and Generative Adversarial Networks (GAN). 多层感知器(MLP)、卷积神经网络(CNN)、递归神经网络(RNN)、反向传播、前馈、自动编码器和生成对抗性网络(GAN)。 |
| 3 | Classification 分类 | Decision trees, random forests, Naive Bayes, support vector machines (SVM), and k-nearest neighbors (KNN). 决策树、随机森林、朴素贝叶斯、支持向量机(SVM)和k近邻(KNN)。 |
| 4 | Clustering 聚类 | K-means clustering, hierarchical clustering, and density-based clustering. 决策树、随机森林、朴素贝叶斯、支持向量机(SVM)和k近邻(KNN)。 |
| 5 | Time series 时序 | Autoregressive integrated moving average (ARIMA), exponential smoothing, and seasonal decomposition. 序列自回归综合移动平均(ARIMA)、指数平滑和季节分解。 |
| 6 | Decision tree | Classification and Regression Trees (CART), Chi-squared Automatic Interaction Detection (CHAID), ID3, and C4.5. 分类和回归树(CART)、卡方自动交互检测(CHAID)、ID3和C4.5。 |
| 7 | Ensemble | Bagging, boosting, stacking, and random forest. 装袋、助推、堆叠和随机森林。 |
图片经博主加工处理而成。
Source: What is Predictive Modeling? Types & Techniques
四、原文作者洞见和博主观察 对消费者感知创意视觉或信息的无形方式做出反应的算法需要大量的变化。在这类情况下,过于严格地遵守品牌标准或活动的有限规则可能会阻碍结果。消费者是非常不同的,我们需要给模型提供燃料(各种数据与算法和模型的组合),使其能够解读这些差异。创造性的变化是必须的。所以我们在选择哪个人工智能公司为我们提供服务时,一定要问清楚,他们的优势在哪里,为什么?
对消费者感知创意视觉或信息的无形方式做出反应的算法需要大量的变化。在这类情况下,过于严格地遵守品牌标准或活动的有限规则可能会阻碍结果。消费者是非常不同的,我们需要给模型提供燃料(各种数据与算法和模型的组合),使其能够解读这些差异。创造性的变化是必须的。所以我们在选择哪个人工智能公司为我们提供服务时,一定要问清楚,他们的优势在哪里,为什么?
在市场营销阶段考虑AI公司的创意能力时(采购需求推出阶段),笔者认为企业应该要求AI供应商关注遗下四个方面哦的有关创新工作:
1. 邮件推送广告 – 创造内容和大范围推送
2. 推送推文或者短信息 – 优化促销内容
3. 网页和APP – 促使完成采购
4. 社会媒体 – 提高客户忠诚度和提高客户存留率
如何选择一个人工智能公司帮助我们做创意营销工作,以下建议或许可以参考:
1.创新
专注于生成人工智能的开创性进展,特别是在机器学习模型和自然语言处理方面。
强调开发和应用先进的人工智能工具,特别是大型语言和扩散模型。
2.项目成功
检查这些公司在跨不同行业的成功业绩记录。
评估这些解决方案对业务流程、创造力和客户投资回报的影响。
3.客户反馈
分析客户的证明和评论,衡量人工智能系统的有效性和影响,进行验证。
4.适应性和进化
评估这些公司如何跟上不断发展的人工智能技术,尤其是生成式人工智能模型和技术。
Sources: Top Generative AI Development Companies of 2024
五、一家国际知名创意人工智能和机器学习公司 – Rapidops
Sources: About Us | Digital Product Development Company
这家公司有多强大!自2008年成立以来,从最新的产品前沿研发,人才,技术,客户需求识别,产品加工和交付,从战略合作伙伴和主要客户,几乎都是世界五百强公司或者头部客户,产品广泛应用于零售,制造业,健康,供应链和物流等各大行业。

为了便于读者后续深入学习数字化营销体系相关的这九种人工智能和机器学习技术,经过与多位同行讨论及前辈老师们的讨教,后续每一篇文章将尽可能按照以下原则,要求和框架进行编写。
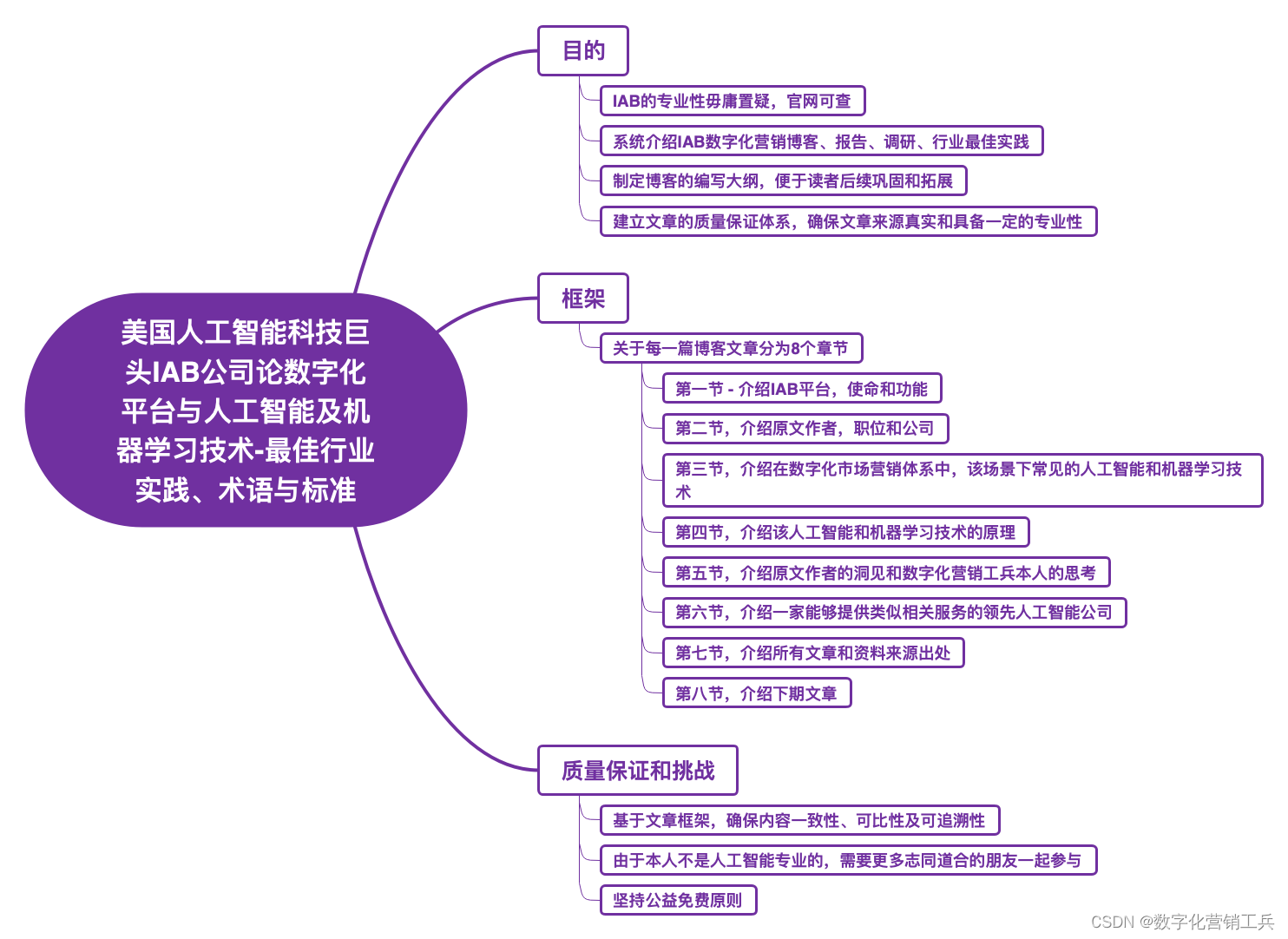 六、文章资料来源及推荐阅读:
六、文章资料来源及推荐阅读:
1. 关于本文作者介绍
Innovator Insights: IBM Watson Advertising's Robert Redmond On The Quest To Tackle Bias In AI-Based AdvertisingMarketing campaigns may be biased towards the brands that create them — they’re trying to promote their own products and services, after all — but Robert Redmond is working to ensure they can be developed based on objective data and analysis. ![]() https://www.brand-innovators.com/news/innovator-insights-ibms-robert-redmond/
https://www.brand-innovators.com/news/innovator-insights-ibms-robert-redmond/
2. Predictive Modeling Techniques: Types, Benefits & Algorithms
Predictive Modeling Techniques: Types, Benefits & AlgorithmsPredictive modeling helps businesses improve workflows, operations, and their bottom line. Learn the benefits, challenges, and algorithms.![]() https://neo4j.com/blog/predictive-modeling-techniques/
https://neo4j.com/blog/predictive-modeling-techniques/
3. The Complete Guide to Predictive Modeling
The Complete Guide to Predictive Modeling | Pecan AIUnlock the power of predictive modeling with our in-depth guide. Learn tools, strategies, and techniques for accurate data analysis and forecasting.![]() https://www.pecan.ai/blog/predictive-modeling/
https://www.pecan.ai/blog/predictive-modeling/
4. Rapidops公司网站
About Us | Digital Product Development CompanyExperience high-quality engineering, proven expertise, teamwork, and commitment to your success with Rapidops.![]() https://www.rapidops.com/about/
https://www.rapidops.com/about/