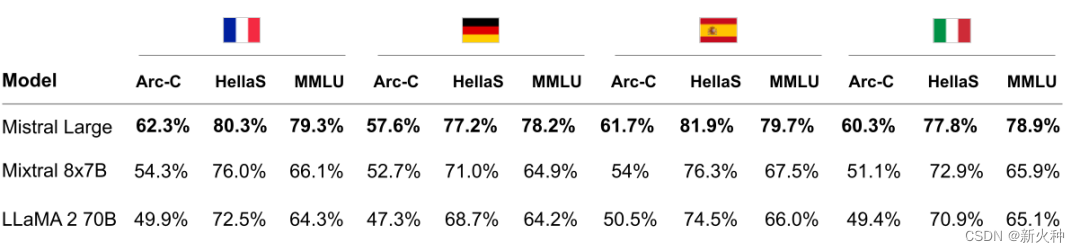
文章目录
- 参考资料
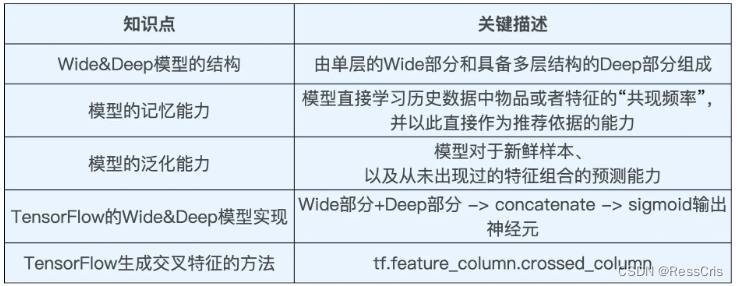
- 模型结构
- 模型的记忆能力
- 模型的泛化能力
- 问题
参考资料
- 见微知著,你真的搞懂Google的Wide&Deep模型了吗?
- keras实现的代码参考
模型结构
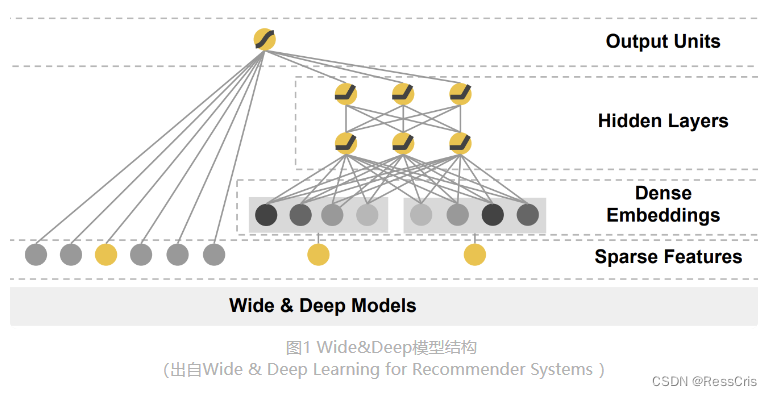
它是由左侧的 Wide 部分和右侧的 Deep 部分组成的。Wide 部分的结构太简单了,就是把输入层直接连接到输出层,中间没有做任何处理。Deep 层的结构稍复杂,就是 Embedding+MLP 的模型结构。
Wide 部分的主要作用是让模型具有较强的“记忆能力”(Memorization),而 Deep 部分的主要作用是让模型具有“泛化能力”(Generalization),因为只有这样的结构特点,才能让模型兼具逻辑回归和深度神经网络的优点,也就是既能快速处理和记忆大量历史行为特征,又具有强大的表达能力,这就是 Google 提出这个模型的动机。
模型的记忆能力
所谓的 “记忆能力”,可以被宽泛地理解为模型直接学习历史数据中物品或者特征的“共现频率”,并且把它们直接作为推荐依据的能力 。
但这类规则有两个特点:一是数量非常多,一个“记性不好”的推荐模型很难把它们都记住;二是没办法推而广之,因为这类规则非常具体,没办法或者说也没必要跟其他特征做进一步的组合。
为什么模型要有 Wide 部分?就是因为 Wide 部分可以增强模型的记忆能力,让模型记住大量的直接且重要的规则,这正是单层的线性模型所擅长的。
模型的泛化能力
“泛化能力”指的是模型对于新鲜样本、以及从未出现过的特征组合的预测能力。
这就体现出泛化能力的重要性了。模型有了很强的泛化能力之后,才能够对一些非常稀疏的,甚至从未出现过的情况作出尽量“靠谱”的预测。
我们学过的矩阵分解算法,就是为了解决协同过滤“泛化能力”不强而诞生的。因为协同过滤只会“死板”地使用用户的原始行为特征,而矩阵分解因为生成了用户和物品的隐向量,所以就可以计算任意两个用户和物品之间的相似度了。这就是泛化能力强的另一个例子。
提了一个 Memorization of feature interaction ⇒ wide part,
deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features.
Memorization can be loosely defined as
learning the frequent co-occurrence of items or features and
exploiting the correlation available in the historical data.
Recommendations based on memorization are usually more topical and
directly relevant to the items on which users have already
performed actions.
memorization
部分倾向于对已经反馈过的历史数据,学习其中的关系。
Generalization, on the other hand, is based on transitivity
of correlation and explores new feature combinations that have never or rarely occurred in the past.
Generalization
cross-product transformation
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ 0 , 1 \phi_k(x) = \prod_{i=1}^d x_i^{c_{ki}} \quad c_{ki} \in {0,1} ϕk(x)=i=1∏dxickicki∈0,1

问题
- cross-product transformation 部分是只适用于one-hot 之后的分类特征吗?那么当分类特征的量很大的时候,这个组合的量不会非常之大吗?
- 也就是说,这个部分是手动构建的,而不是自动生成的。