电影推荐系统自从机器学习时代开始以来就不断发展,逐步演进到当前的 transformers 和向量数据库的时代。
在本文中,我们将探讨如何在向量数据库中高效存储数千个视频文件,以构建最佳的推荐引擎。

在众多可用的向量数据库中,我们将关注 Qdrant DB,因为它具有独特的特性——HNSW ANN 搜索算法,正如我在之前的文章中讨论的那样。
传统推荐系统
随着支持向量机(SVM)等机器学习算法的发展,引入 transformers 到人工智能领域,传统电影推荐系统得以形成。电影推荐系统利用机器学习算法预测用户对电影的偏好和评分。这些系统主要分为三种类型:
- 协同过滤:通过收集许多具有相似观点的用户的偏好来预测用户的兴趣。
- 基于内容的过滤:根据物品的属性和描述推荐物品,重点关注用户的过去互动。
- 混合系统:结合协同和基于内容的方法,以提高效果,并解决冷启动和数据稀疏等问题。

各种机器学习技术,如最近邻算法用于基于实例的学习,矩阵分解用于协同过滤,以及使用神经网络的深度学习,有助于提高推荐系统的质量。这些系统面临冷启动问题和数据稀疏等挑战。伦理考虑、可扩展性以及整合背景信息进一步增加了设计有效和负责任的推荐系统的复杂性。
向量数据库的引入
向量数据库已经成为进行高效相似性搜索的有益工具。在电影推荐系统中,使用相似性搜索特别有用,其目标是找到与用户已经观看并喜欢的电影相似的电影。
通过将电影表示为高维空间中的向量,我们可以利用距离度量(如余弦相似性或欧氏距离)来识别彼此“接近”的电影,表示它们相似。

随着电影和用户数量的增长,数据库的规模也在增大。向量数据库旨在处理大规模数据,并保持高查询性能。这种可扩展性对于电影推荐系统至关重要,特别是对于那些使用庞大的电影库和用户基础的大型流媒体平台。
在这个背景下,我们将使用 Qdrant 数据库,因为它利用快速的近似最近邻搜索,具体来说是 HNSW 算法与余弦相似性搜索。
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

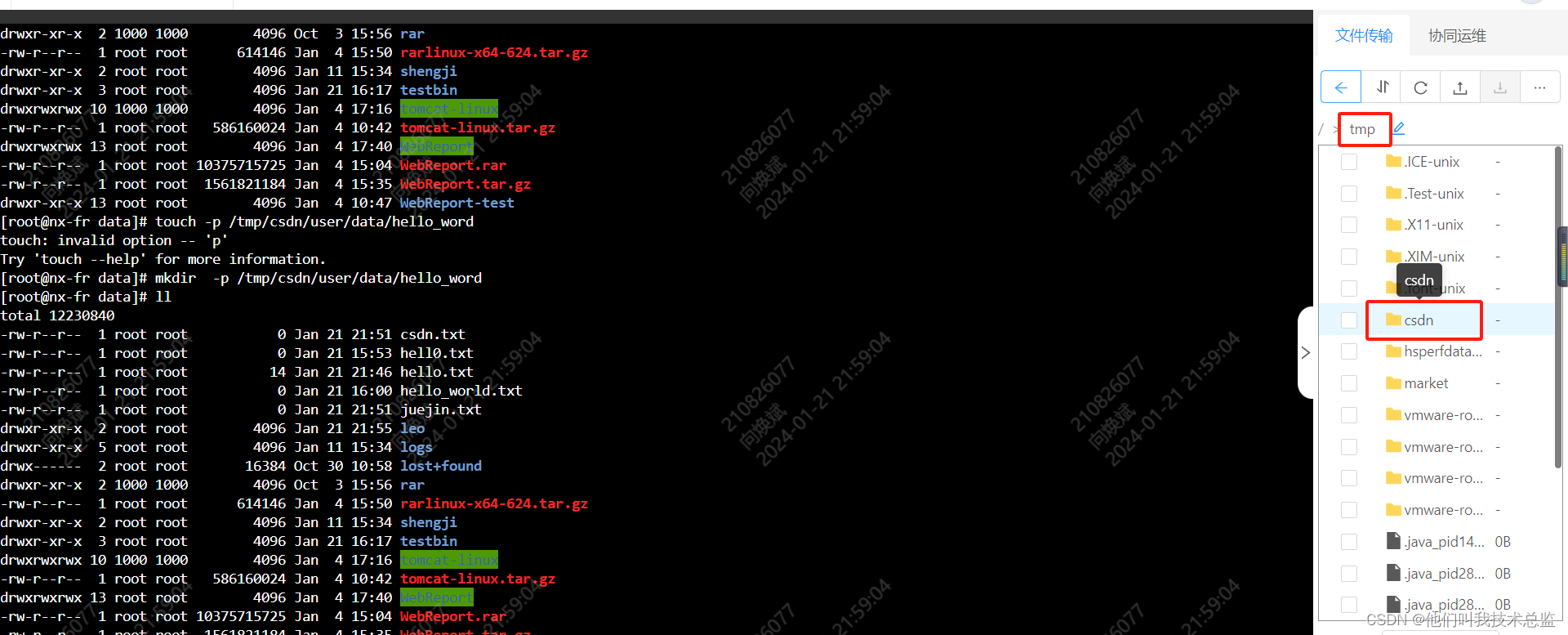
推荐系统架构
在使用向量数据库的同时,让我们了解一下这里的推荐系统是如何工作的。电影的推荐基于模型在一个电影中观察到的情感。该架构分为两个部分:
候选生成
候选生成是推荐系统功能的最重要部分。对于数十万个视频,初始步骤涉及根据口音或语言对内容进行筛选。例如,对于一部西班牙电影,它将在推荐中仅显示西班牙电影。这个筛选过程称为启发式筛选。

第二步是根据视频的转录将其转换为文本嵌入。Hugging Face上有许多模型可以将文本信息转换为向量嵌入。然而,为了获得文本信息,我们首先需要提取视频的音频格式。使用像 Whisper 或 SpeechRecognition 这样的音频转文本模型,我们可以检索文本信息作为转录。
利用嵌入模型,我们将文本信息转换为向量嵌入。将这些向量存储在一个安全可靠的数据库中至关重要。此外,向量数据库简化了我们的相似性搜索。我们将保存嵌入到 Qdrant 数据库中。
在非常短的响应时间内,我们将基于Qdrant数据库的余弦相似性搜索获取相似的视频。这检索相似视频构成了候选生成的最后一步。
重新排序
重新排序主要是在推荐系统中进行的,以根据文本信息中表达的情感来排列电影。借助大型语言模型,我们将能够获得文本信息的意见分数。根据意见分数,电影将被重新排名进行推荐。

代码实现与 Qdrant
在了解了推荐系统的架构之后,现在是时候在代码中实现理论了。我们理解了理论,知道如何分析电影转录的情感,但关键问题是如何将mp4格式的视频文件转换为文本嵌入。
对于这个代码实现,我从YouTube上提取了30个电影预告片。我们需要安装将来使用的重要库。
!pip install -q torch
!pip install -q openai moviepy
!pip install SpeechRecognition
!pip install -q transformers
!pip install -q datasets
!pip install -q qdrant_client
然后,我们将导入在代码实现中需要的所有包。
import os
import moviepy.editor as mp
import os
import glob
import speech_recognition as sr
import csv
import numpy as np
import pandas as pd
from qdrant_client import QdrantClient
from qdrant_client.http import models
from transformers import AutoModel, AutoTokenizer
import torch
现在,我们将创建一个目录,将在其中保存我们的音频转录。
# 指定您的路径
path = "/content/my_directory"
# 创建目录
os.makedirs(path, exist_ok=True)
在创建目录之后,我们将使用以下代码将视频转换为文本信息:
# 包含视频文件的目录
source_videos_file_path = r"/content/drive/MyDrive/qdrant_videos"
# 用于存储音频文件的目录
destination_audio_files_path = r"/content/my_directory/audios"
# 存储转录的CSV文件
csv_file_path = r"/content/my_directory/transcripts.csv"
# 如果目标目录不存在,则创建目录
os.makedirs(destination_audio_files_path, exist_ok=True)
# 初始化识别器类(用于识别语音)
r = sr.Recognizer()
# 以写模式打开CSV文件
with open(csv_file_path, 'w', newline='') as csvfile:
# 创建CSV写入器
writer = csv.writer(csvfile)
# 写入标题行
writer.writerow(["Video File", "Transcript"])
# 逐帧处理视频
for video_file in glob.glob(os.path.join(source_videos_file_path, '*.mp4')):
# 将视频转换为音频
video_clip = mp.VideoFileClip(video_file)
audio_file_path = os.path.join(destination_audio_files_path, os.path.basename(video_file).replace("'", "").replace(" ", "_") + '.wav')
video_clip.audio.write_audiofile(audio_file_path)
# 将音频转录为文本
with sr.AudioFile(audio_file_path) as source:
# 读取音频文件
audio_text = r.listen(source)
# 将语音转换为文本
try:
transcript = r.recognize_google(audio_text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
transcript = "Error: Could not understand audio"
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
transcript = "Error: Could not request results from Google Speech Recognition service; {0}".format(e)
# 将转录写入CSV文件
writer.writerow([video_file, transcript])
然后,我们将在数据框格式中查看我们的转录。
data = pd.read_csv('/content/my_directory/transcripts.csv')
data.head()
有一些“SpeechRecognition”无法理解的转录,因此我们将从数据框中消除这一行。
data = data[~data['Transcript'].str.startswith('Error')]
data.head()
现在,我们将创建一个具有内存数据库的QdrantClient实例。
client = QdrantClient(":memory:")
我们将创建一个集合,其中将存储我们的向量嵌入,使用余弦相似性搜索测量距离。
my_collection = "text_collection"
client.recreate_collection(
collection_name=my_collection,
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE)
)
我们将使用一个预训练模型来帮助我们从数据集中提取嵌入层。我们将使用transformers库和GPT-2模型来完成这个任务。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained('gpt2')
model = AutoModel.from_pretrained('gpt2')#.to(device) # 切换到GPU
我们需要提取电影名称并创建一个新列,以便我们知道哪些嵌入属于哪部电影。
def extract_movie_name(file_path):
file_name = file_path.split("/")[-1] # 获取路径的最后一部分
movie_name = file_name.replace(".mp4", "").strip()
return movie_name
# 应用该函数以创建新列
data['Movie_Name'] = data['Video File'].apply(extract_movie_name)
# 显示数据框
data[['Video File', 'Movie_Name', 'Transcript']]
现在,我们将创建一个帮助函数,通过它我们将为每个电影预告片转录获取嵌入。
def get_embeddings(row):
tokenizer = AutoTokenizer.from_pretrained('gpt2')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
inputs = tokenizer(row['Transcript'], padding=True, truncation=True, max_length=128, return_tensors="pt")
# 对以下操作禁用梯度计算。
with torch.no_grad():
outputs = model(**inputs).last_hidden_state.mean(dim=1).cpu().numpy()
# 返回计算得到的嵌入。
return outputs
然后,我们将嵌入函数应用于我们的数据集。之后,我们将保存嵌入,以便不必再次加载它们。
data['embeddings'] = data.apply(get_embeddings, axis=1)
np.save("vectors", np.array(data['embeddings']))

现在,我们将为每个电影转录创建一个包含元数据的负载。
payload = data[['Transcript', 'Movie_Name', 'embeddings']].to_dict(orient="records")
我们将创建一个用于标记化嵌入的辅助函数。然后,我们将循环遍历“Transcript”列中的每个转录,以创建文本嵌入。
# 设置向量嵌入的预期大小
expected_vector_size = 768
# 定义用于标记化的均值池化函数
def mean_pooling(model_output, attention_mask):
# 从模型输出中提取标记嵌入
token_embeddings = model_output[0]
# 将关注掩码扩展到与标记嵌入的大小匹配
input_mask_expanded = (attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float())
# 计算考虑到关注掩码的标记嵌入的总和
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
# 计算关注掩码的总和(夹紧以避免除零错误)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# 返回均值池化的嵌入
return sum_embeddings / sum_mask
# 初始化列表以存储文本嵌入
text_embeddings = []
# 遍历“data”变量的“Transcript”列中的每个转录
for transcript in data['Transcript']:
# 对转录进行标记化,确保填充和截断,并返回PyTorch张量
inputs = tokenizer(transcript, padding=True, truncation=True, max_length=128, return_tensors="pt")
# 使用模型和标记化的输入执行推断
with torch.no_grad():
embs = model(**inputs)
# 使用定义的函数计算均值池化的嵌入
embedding = mean_pooling(embs, inputs["attention_mask"])
# 确保嵌入的大小正确,通过修剪或填充
embedding = embedding[:, :expected_vector_size]
# 将得到的嵌入追加到列表中
text_embeddings.append(embedding)
为了在Qdrant数据库集合中为每个转录分配明确的ID,我们将创建一个ID列表,然后更新组合的ID、向量和负载。
ids = list(range(len(data)))
# 将PyTorch张量转换为浮点数列表
text_embeddings_list = [[float(num) for num in emb.numpy().flatten().tolist()[:expected_vector_size]] for emb in text_embeddings]
client.upsert(collection_name=my_collection,
points=models.Batch(
ids=ids,
vectors=text_embeddings_list,
payloads=payload
)
)
使用情感分析模型,您可以生成情感分数,其中情感极性在-1和1之间计算。分数为-1表示负面情感,0表示中性情感,1表示正面情感。
from textblob import TextBlob
def calculate_sentiment_score(text):
# 创建TextBlob对象
blob = TextBlob(text)
# 获取情感极性(-1到1,其中-1为负面,0为中性,1为正面)
sentiment_score = blob.sentiment.polarity
return sentiment_score
# 示例用法:
text_example = data['Transcript'].iloc[0]
sentiment_score_example = calculate_sentiment_score(text_example)
print(f"Sentiment Score: {sentiment_score_example}")
对于此示例,生成的情感分数将为0.75。现在,我们将将计算情感分数的辅助函数应用于“data”数据框。
data['Sentiment Score'] = data['Transcript'].apply(calculate_sentiment_score)
data.head()
您可以取每个电影转录的向量嵌入的平均值,并与情感分数结合以获得最终的意见分数。
data['avg_embeddings'] = data['embeddings'].apply(lambda x: np.mean(x, axis=0))
data['Opinion_Score'] = 0.7 * data['avg_embeddings'] + 0.3 * data['Sentiment']
在上述代码中,我为嵌入分配了更大的权重,因为它们捕获语义内容和电影转录之间的相似性。内在内容相似性在确定总体意见分数时更为关键。 “Sentiment”列定义了电影转录的情感语气。我为情感分数分配了较低的权重,因为情感作为因素在计算总体意见分数时不像语义内容那样关键。权重是任意的

然后创建一个电影推荐函数,其中您传递电影名称并获取所需数量的推荐电影。
def get_recommendations(movie_name):
# 找到对应于给定电影名称的行
query_row = data[data['Movie_Name'] == movie_name]
if not query_row.empty:
# 将'Opinion_Score'列转换为NumPy数组
opinion_scores_array = np.array(data['Opinion_Score'].tolist())
# 将'Opinion_Score'向量上插入到Qdrant集合
opinion_scores_ids = list(range(len(data)))
# 将'Opinion_Score'数组转换为列表的列表
opinion_scores_list = opinion_scores_array.reshape(-1, 1).tolist()
client.upsert(
collection_name=my_collection,
points=models.Batch(
ids=opinion_scores_ids,
vectors=opinion_scores_list
)
)
# 基于要查找相似电影的意见分数定义查询向量
query_opinion_score = np.array([0.8] * 768) # 根据需要进行调整
# 执行相似性搜索
search_results = client.search(
collection_name=my_collection,
query_vector=query_opinion_score.tolist(),
limit=3)
# 从搜索结果中提取电影推荐
recommended_movie_ids = [result.id for result in search_results]
recommended_movies = data.loc[data.index.isin(recommended_movie_ids)]
# 显示推荐电影
print("Recommended Movies:")
print(recommended_movies[['Movie_Name', 'Opinion_Score']])
else:
print(f"Movie '{movie_name}' not found in the dataset.")
# 示例用法:
get_recommendations("Star Wars_ The Last Jedi Trailer (Official)")
通过这样,我们能够使用Qdrant数据库创建一个电影推荐系统。

结论
矢量数据库有许多用途。在这些用例中,电影推荐系统在余弦相似性搜索和大型语言模型的帮助下取得了显著的改进。

使用 Qdrant 数据库创建电影推荐系统非常有趣、令人兴奋,也很容易。
借助 Qdrant 的最佳近似最近邻搜索和处理大型负载的能力,您可以创建自己的数据集,并尽情尝试基于矢量搜索的电影推荐系统。来自akriti.upadhyay