作者 | 通用搜索产品研发组
导读
本文简单介绍了百度搜索Push个性化的发展过程,揭示了面临的困境和挑战:如何筛选优质物料、如何对用户精准推荐等。我们实施了一系列策略方法进行突破,提出核心的解决思路和切实可行的落地方案。提升了搜索DAU和点击率,希望本文的内容能为相关从业者带来启发和借鉴价值。
全文5573字,预计阅读时间14分钟。
01 背景
百度搜索一直以来都致力于为用户提供快速、准确的信息获取服务。而搜索Push是百度搜索的一种重要功能,可以帮助用户快速获取他们所需的信息,同时还可以主动触达用户。与传统信息流Push不同,搜索Push通过query的形式推送给用户,用户可以获取自己需要的信息。这种推送方式更加精准,从而更好地满足自己的需求。用户可以通过搜索Push快速获取自己需要的信息,从而更加频繁地使用百度搜索,进而提升搜索DAU。
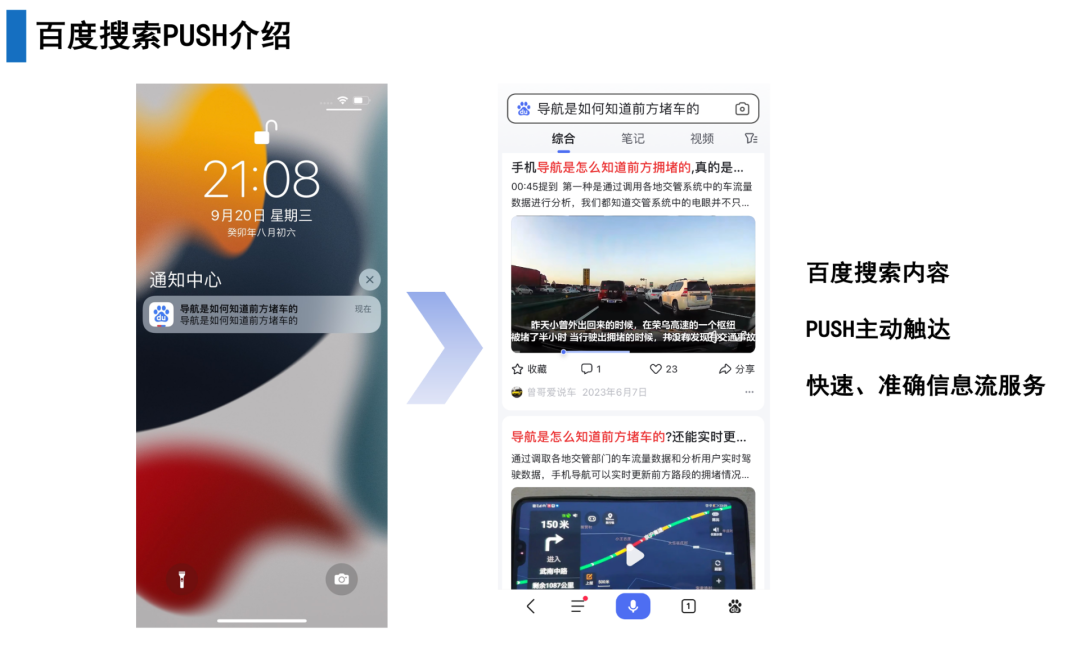
百度在Push方面也拥有着相当的规模和影响力。然而,百度搜索Push在整体Push中的发送量、点击量UV占比较小,搜索Push还有很大的增长空间,需要采取高效的策略来提升点击率。从以下几个方面进行优化和提升:
1.筛选优质物料:目前搜索物料较为充裕,需从海量的数据中筛选出能够通过审核、具有较高点击率(ctr)的物料。这需要建立一套完善的筛选机制,从内容质量、用户需求、合规性等多个维度进行评估和筛选。
2.用户精准推荐:精准触达在推荐系统中具有重要的作用,可以提高用户体验,满足用户的兴趣和需求。在Push推送中,需要通过高效的策略算法,精确找到合适的人群进行推送。这需要对用户画像、兴趣爱好、行为习惯等多方面进行深入分析和挖掘。
综上,搜索Push作为一种便捷的信息获取服务,不仅可以帮助用户快速获取自己需要的信息,还可以主动触达用户,业务目标是在不影响Push大盘的基础上扩大个性化搜索push影响面,提升搜索的DAU。
02 整体方案设计
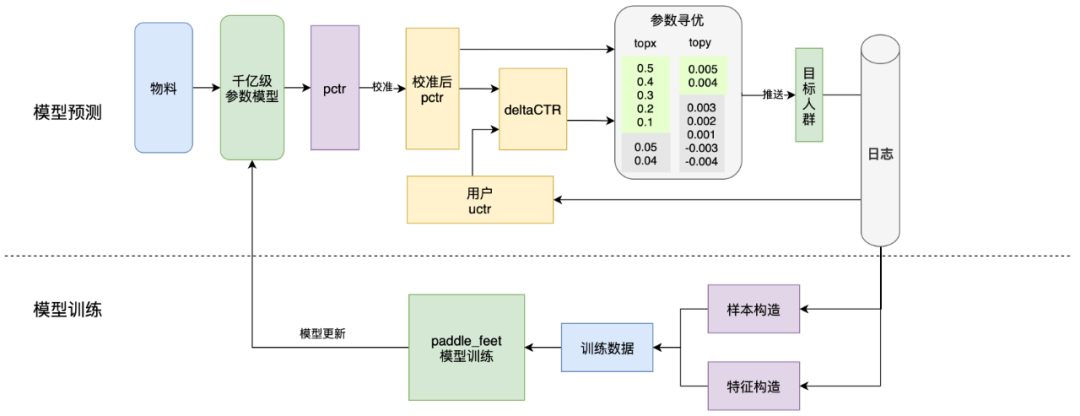
整体流程包括物料生产、搜Push策略以及与Push下发等环节。这些环节相互关联,共同构成了整个流程。
1.物料生产:是整个流程的关键,我们通过人工审核、LLM大模型改写等方式,筛选出优质的物料。
2.搜索push策略:是整个流程的重要环节,通过高效的模型算法,找到与用户需求和兴趣相匹配的内容,并进行精准推送。
3.push通路:是整个流程中不可或缺的一环,搭建一个高效的搜索push通路的可以帮助搜索更好地进行推广。
2.1 搜索push通路建设
搜索Push作为百度APP Push的重要来源,需要建设稳定、高效的通路进行数据下发。需要从多个方面进行优化和改进,包括离线匹配的高效性、策略匹配的准确性和物料的质量性等方面。只有这样,才能更好地满足用户的需求和提高用户的使用体验。按照上述各方面的要求,搜索Push的总体流程如下:
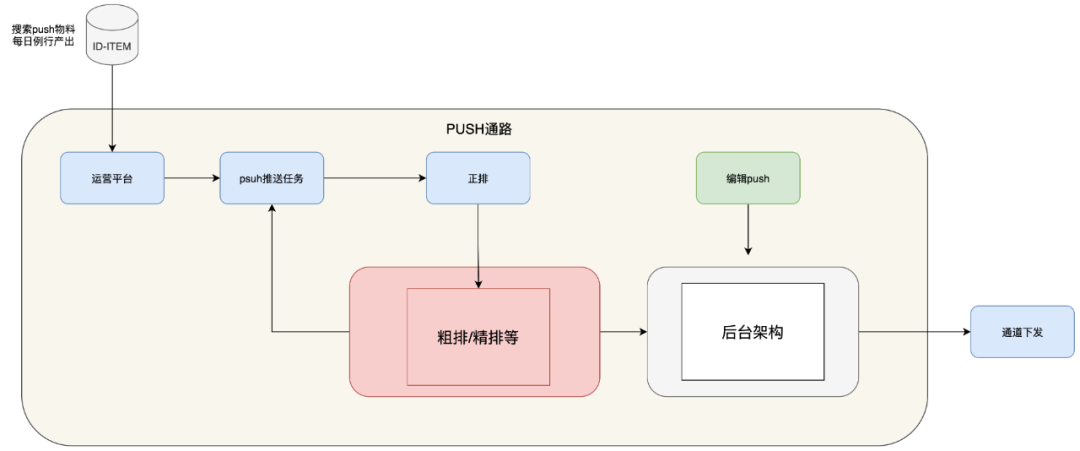
在搜索Push场景下,需要下发的数据由<ID,ITEM>对组成。在经过粗排、精排等逻辑处理后,对各个通路来的物料进行打分。最终,选取分数最高的物料进行下发。
面临现有机制的情况下,搜索Push的挑战主要有两点:第一,需要有足够优质的物料。第二,需要有足够精确的模型和策略,将物料与用户的需求相匹配。
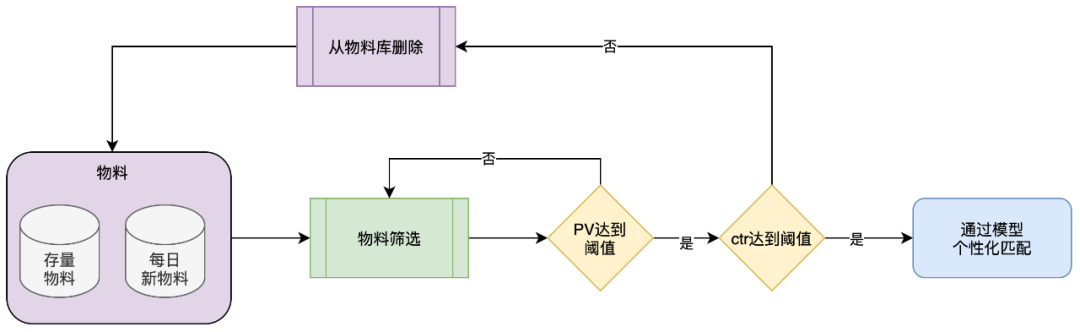
2.2 筛选优质物料
基于搜索物料池,我们进行了两个版本的尝试:第一版根据不同的策略规则从搜索物料池中挖掘出万级物料进行个性化推荐。第二版是基于后验的优质物料筛选方式。

在挖掘出优质物料之后,运营同学可以对这些物料进行进一步的筛选和优化,以确保其质量和效果。在这个过程中,我们保证了物料的多样性和丰富性,避免了重复和过度相似的内容。并尝试使用LLM大模型技术对物料摘要进行改写,可以更好地适应搜索引擎的算法和用户的需求,从而提高物料的点击率和转化率,筛选后经过后验分析,得出优质的物料进入精排模型,详细设计如下:
2.3 用户精准推荐:模型算法优化
我们从初期的双塔模型,到全连接模型,再到升级模型特征、网络结构,经过了几个版本的迭代升级,并借助paddlepaddle机器学习平台,完成了千亿级参数离散模型训练,最后综合考虑pctr和用户uctr的bias,在模型中引入deltaCTR策略。

2.3.1 提升模型准确性
准确性的核心在于通过对用户画像、兴趣爱好、行为信息等多方面进行深入分析和挖掘,通过高效的模型算法,找到与用户需求和兴趣相匹配的内容,并进行精准推送,提高推送效果和用户体验。在整个过程中,特征非常重要,我们对特征进行了迭代升级,构建搜索push专有的画像,和行为序列,并引入交叉特征,id类特征等,AUC提升显著。列举了以下几个关键特征:
1.itemid特征:由于推送的文章均是有过点击行为的文章,id类特征在训练样本中存在,模型可以学习到细粒度的文章信息。
2.用户id特征:用户id特征比较稀疏,因此我们回溯了较长时间的样本,保证模型可以更好拟合出的用户id特征
3.push场景画像和序列信息:这些特征的加入使得模型能够更好地理解数据和用户行为,从而进一步提升DAU

2.3.2 pctr校准
为什么要校准?
由于正负样本不均衡,在构造模型样本时,对样本进行了负采样通常可以提升模型精度,但是pctr值会发生变化,与真实ctr差距扩大。建立deltaCTR模型时会用到pctr减uctr,负采样带来的pctr值的变化会对最终结果产生影响,因为需要校正。
校准公式:
p c t r ( 校准后 ) = c t r s / p c t r m ∗ p c t r pctr(校准后)=ctr_s / pctr_m* pctr pctr(校准后)=ctrs/pctrm∗pctr
其中, c t r s ctr_s ctrs为模型训练样本中的 c t r ctr ctr, p c t r a pctr_a pctra为模型预测 p c t r pctr pctr打分的均值。
以上是简单的校准逻辑,后续会进行迭代升级,主要有以下几种尝试方法:
方式一:基于负样本采样率调整ctr
来源:Facebook公开的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》里面提到一种基于负采用率来进行ctr纠偏的计算公式
q = p p + ( 1 − p ) w q=\frac{p}{p+\frac{(1-p)}{w} } q=p+w(1−p)p其中,p是预估值,w是负采样的比例,q是校准后的ctr值。
方式二:保序回归
保序回归法目前是业界最常用的校准方法。常见的算法是保序回归平滑校准算法(Smoothed Isotonic Regression,SIR)。
保序回归法的整体思想就是:不改变原有数据的pctr排序,仅在原有pctr的排序上进行纠偏。最终纠偏出来的ctr数据分布的单调性不变,AUC指标不变。
整体执行步骤如下:
Step1—区间分桶
首先将pctr值从小到大进行排序,然后按照区间分为K个桶。假设我们分为100个桶:(0,0.01], (0.01,0.02], (0.02,0.03],…, (0.99,1]。这里我们认为精排模型给出pctr值是具有参考意义的,同一个区间里的PV请求具有近似的真实点击率,每一个区间可作为一个合理的校准维度(分簇维度)。然后实际应用时,我们再统计每一个桶里的后验ctr值。比如今天线上一共有1000次预估的pctr落在了桶 (0.02,0.03]之间,然后我们统计这1000个预估的后验CTR,假设后验CTR为0.23%。关于每个桶里Pctr和Actr平均值的计算公式如下:
第 i i i个桶的后验 C T R CTR CTR为 A C T R i = Σ 点击 P V Σ 曝光 P V ACTRi= \frac{\Sigma 点击PV}{\Sigma 曝光PV} ACTRi=Σ曝光PVΣ点击PV ,预估 c t r ctr ctr均值为 p c t r pctr pctr平均值 i = Σ p c t r Σ 曝光 P V i= \frac{\Sigma pctr}{\Sigma 曝光PV} i=Σ曝光PVΣpctr
Step2—桶间合并
如果说后验ctr的值超出了对应分桶的pctr取值区间怎么办?假如原本分桶在(0.02,0.03]之间结果的后验ctr为0.35%,这时已经进入到了下一个桶里了(0.03,0.04]。如果我们将原本pctr在(0.02,0.03]桶里面的值往下一个桶里的区间值进行校准,这就破坏了原有桶之间的顺序,保序回归的基本逻辑是不能破坏原pctr的顺序。此时我们需要把(0.02,0.03]和(0.03,0.04]桶进行合并得到新的桶(0.02,0.04],再重新对落入两个桶里的数据进行后验ctr统计,得到新桶里面的 actr和pctr平均值。我们以pctr为x,actr为y轴,最终得到一个如下图所示单调递增的散点图:
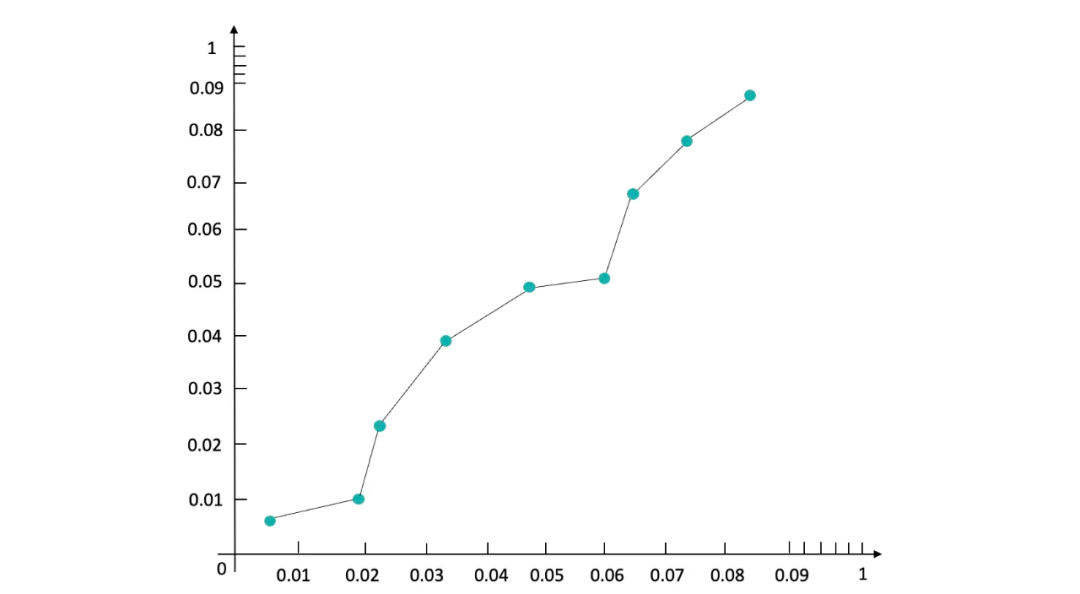
Step3—桶间插值分段校准
我们需要基于上述散点图去构造一个校准函数,输入x值以后就可以输出校准后的y值。如果直接拟合一个 y = k x + b y = kx + b y=kx+b函数,最终预估的结果不够平滑。目前业界的标准做法都是构造分段校准函数。
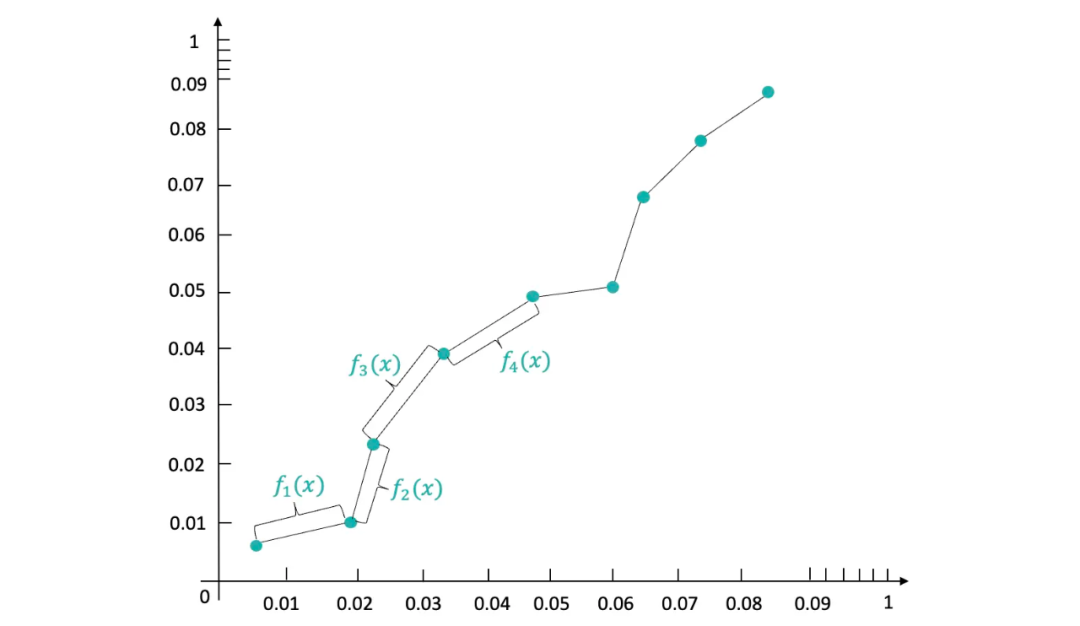
如上图所示,我们将两个桶之间坐标点连接起来,然后去构造一个分段的 y = k x + b y = kx + b y=kx+b校准函数,假设pctr一共分为了100个桶,那么最终就构造100个分段校准函数,这样既保证单调性,又保证平滑地校准。已知两点坐标计算对应的 y = k x + b y = kx + b y=kx+b。
2.4 基于deltaCTR策略设计
通过对大量物料的后验ctr表现进行排序,选取出表现最好的topK个物料。使用模型对物料打分,对预测的pctr值进行校准,以确保预测结果更加准确。然后,建立deltaCTR策略,即根据校正后的pctr值和用户uctr计算物料的deltaCTR,即增量点击率。并根据pctr和deltaCTR两个队列,找到最佳的参数组合,从而制定出最佳的推送策略。最后,我们需要选择合适的人群进行推送。在选择人群时,我们还需要考虑受众的规模和受众的活跃度等因素。
综上所述,通过物料的后验ctr表现选取出topK个物料,通过模型对物料pctr打分后校准,建立deltaCTR策略寻找最佳的参数,选择合适的人群进行推送是提高推送效果的关键步骤。在实际操作中,我们需要不断优化和调整这些步骤,以确保推送效果的最大化。
2.4.1 兼顾收益和DAU最大
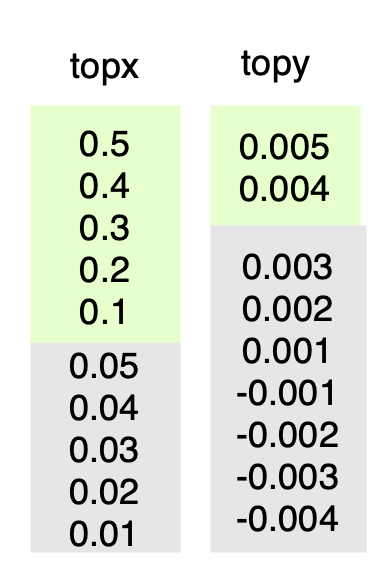
我们需要每天下发topK个物料。在k个候选物料确定的情况下,需要精准地寻找目标人群进行下发。通常来说,模型打分越高,所带来的点击率就越高,进而能够带来更高的DAU。因此,按照pctr排序取topx,可以保证带来更多的点击。同时,由于用户本身存在自己的uctr,因此我们需要考虑这个bias因素对模型pctr的影响。为了更准确地评估系统带来的收益,我们可以按照模型预测点击率pctr减去用户点击率uctr得到deltaCTR,然后按照deltaCTR排序取topy,我们可以更准确地评估每个物料对系统带来的实际收益。
因此,topx和topy这两个参数寻优非常重要。
2.4.3 deltaCTR参数寻优
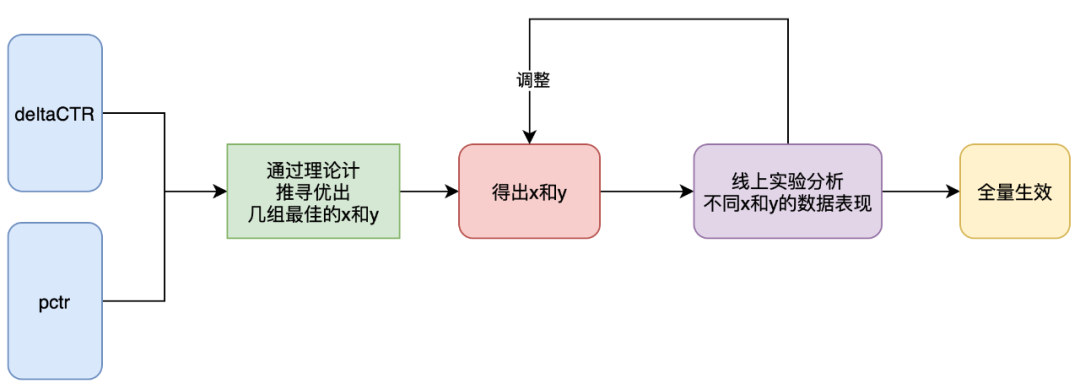
在我们的策略中,使用了两个重要的参数a和b进行优化。通过调整这两个参数,我们得到了不同的topx和topy数据结论。当a和b的值不同时,x和y的表现会有所不同。因此,我们决定采用离线分析和在线实验相结合的方法,以找到最佳的参数组合。
在离线分析阶段,我们根据历史数据和理论推导,选择了几个可能的a和b的组合。然后,我们在线上实验中测试了这些组合的性能。通过不断调整x和y参数,我们发现了一些表现优秀的参数组合。最后,我们选择了一组最佳的参数组合,进行全量。
这一组最佳的参数组合是通过大量的实验和数据分析得出。后续将不断优化我们的模型和参数,以提高我们的整体性能和效果。
2.4.3.1 离线理论推导
在后验数据的基础上,我们针对x和y进行优化,旨在确保实验组和对照组的CTR保持一致,同时实现点击量的最大化。这种优化方法可以通过调整x和y的参数,使得实验组和对照组的点击率达到相等水平,进而最大化整体点击量。在实施这种优化策略时,需要注意数据采集和分析的准确性,以及实验组和对照组的平衡性。具体步骤:
1、计算模型预测的CTR(pctr)
2、 计算用户活跃度分群cluster_ctr和实际用户uctr
3、 处理不置信的uctr值
4、 计算deltaCTR
5、 对pctr和deltaCTR进行排序
将pctr和deltaCTR进行排序,得到两个队列,如下:
队列1: s o r t D e l t a C T R = s o r t ( d e l t a C T R ) sortDeltaCTR=sort(deltaCTR) sortDeltaCTR=sort(deltaCTR)
队列2: s o r t P c t r = s o r t ( p c t r ) sortPctr=sort(pctr) sortPctr=sort(pctr)
6、 寻找最优x和y值
设置不同的 t o p x topx topx和 t o p y topy topy,可以得到不同的 f ( x ) f(x) f(x)和 g ( y ) g(y) g(y),为了方便起见,本文将x和y按照从0%到100%,每10%作为一个分段进行取值分析。其中:
f ( x ) = s u m ( d e l t a C T R ) f(x)=sum(deltaCTR) f(x)=sum(deltaCTR),当 s o r t D e l t a C T R sortDeltaCTR sortDeltaCTR取 t o p x topx topx
g ( y ) = s u m ( d e l t a P C T R ) g(y)=sum(deltaPCTR) g(y)=sum(deltaPCTR),当 s o r t P c t r sortPctr sortPctr取 t o p y topy topy,且 y y y的<用户, i t e m > p a i r item>pair item>pair对,不在 x x x中
通过寻找 x x x和 y y y,保证当 a ∗ f ( x ) + b ∗ g ( y ) = 0 a*f(x)+b*g(y)=0 a∗f(x)+b∗g(y)=0时, s u m ( p c t r ) sum(pctr) sum(pctr)最大。其中 a a a和 b b b是超参数。
伪代码如下:

通过理论计算,经过几组参数的选取,在不同实验参数下,得出不同的结论如下:
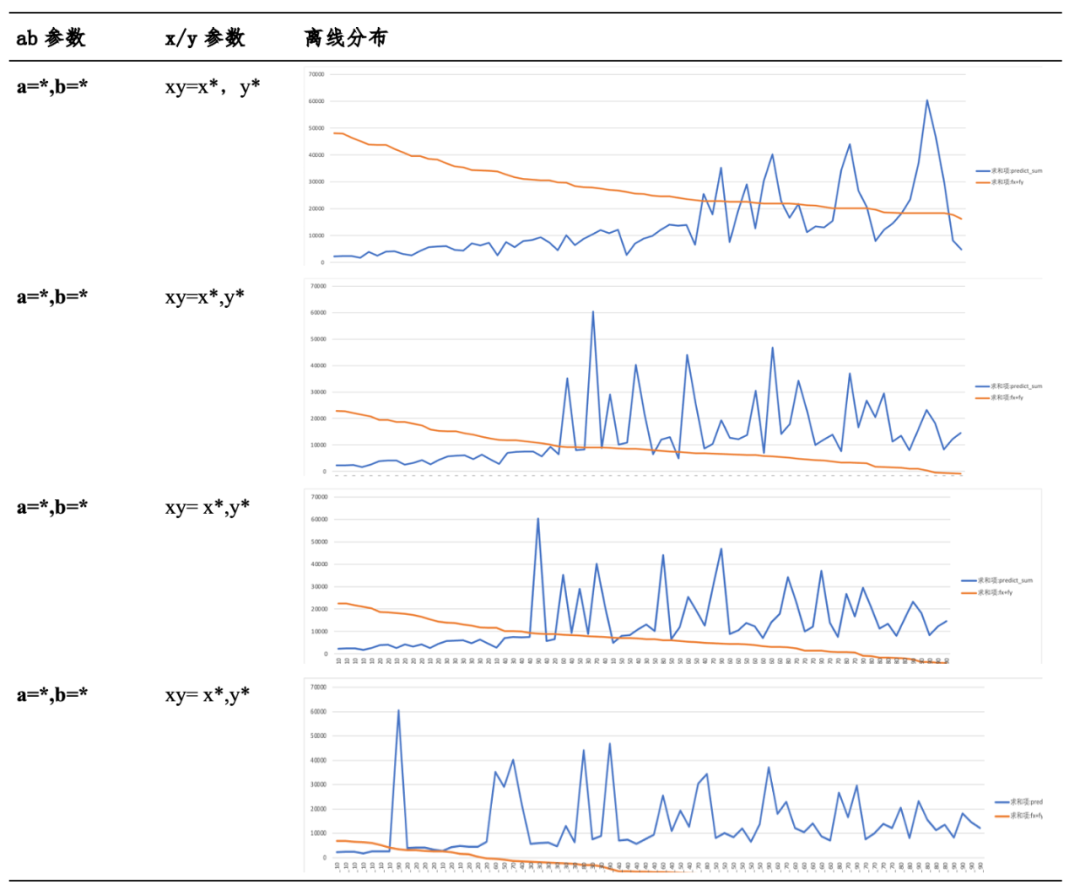
2.4.3.2 离线分析和在线实验相结合
离线分析和在线实验是两种不同的数据分析方法,各有其优缺点。离线分析通常在数据收集后进行,可以处理大量数据,但无法实时反映数据的变化。在线实验则可以实时监测数据的变化,但通常缺乏理论支撑,存在波动的影响。为了克服这两种方法的缺点,可以采用离线分析和在线实验相结合的方法。在离线分析阶段,可以对大量数据进行处理和分析,以发现数据中的模式和趋势。然后,可以将这些模式和趋势应用于在线实验中,以实时监测数据的变化。最终我们选择三组比较好的x和y参数分别是
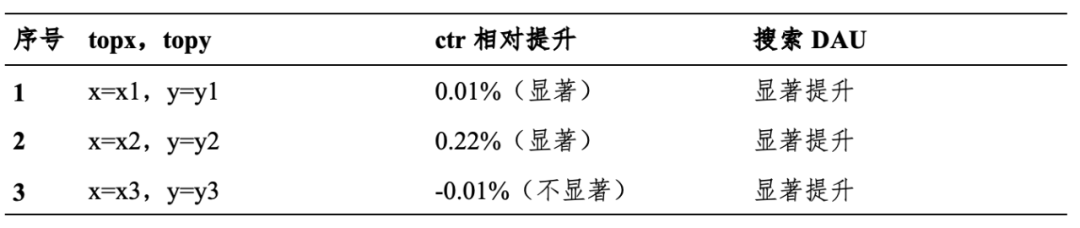
△注:x1~x3,y1~y3均是线上真实数据,不便于公开。
三组实验,DAU均显著提升。其中,x=x1,y=y1,ctr相比大盘提升最大;x=x3,y=y3,DAU提升最大,但ctr存在略微负向不显著。后续继续对x=x3,y=y3进行优化,通过模型迭代、pctr校准优化等提升整体ctr和DAU。
03 小结
本文主要介绍了百度搜索Push个性化方案的设计和落地过程。通过挖掘优质物料、迭代模型算法等步骤,我们成功地提高了搜索Push的点击率和提升了搜索DAU。在模型算法迭代方面,我们重点优化了模型准确性、pctr校准和基于deltaCTR策略设计。离线分析和在线实验相结合的方法帮助我们找到了最佳的参数组合,进一步提高了整体效果。实验结果表明,我们的方案在DAU和ctr提升方面均取得了显著成果。未来,我们将继续优化模型和参数,以实现更高的性能提升。
——END——
推荐阅读
数据交付变革:研发到产运自助化的转型之路
百度搜索exgraph图执行引擎设计与实践
百度搜索&金融:构建高时效、高可用的分布式数据传输系统
“踩坑”经验分享:Swift语言落地实践
移动端防截屏录屏技术在百度账户系统实践