基于Hadoop的异构网络协同过滤推荐算法设计
基于Hadoop的异构网络协同过滤推荐算法设计
Design of Heterogeneous Network Collaborative Filtering Recommendation Algorithm based on Hadoop
目录
目录 2
摘要 3
关键词 4
第一章 引言 4
1.1 研究背景 4
1.2 研究意义 5
1.3 国内外研究现状 7
1.4 本文研究内容与结构安排 8
第二章 相关技术介绍 10
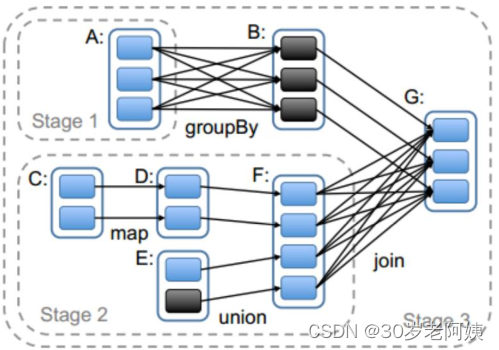
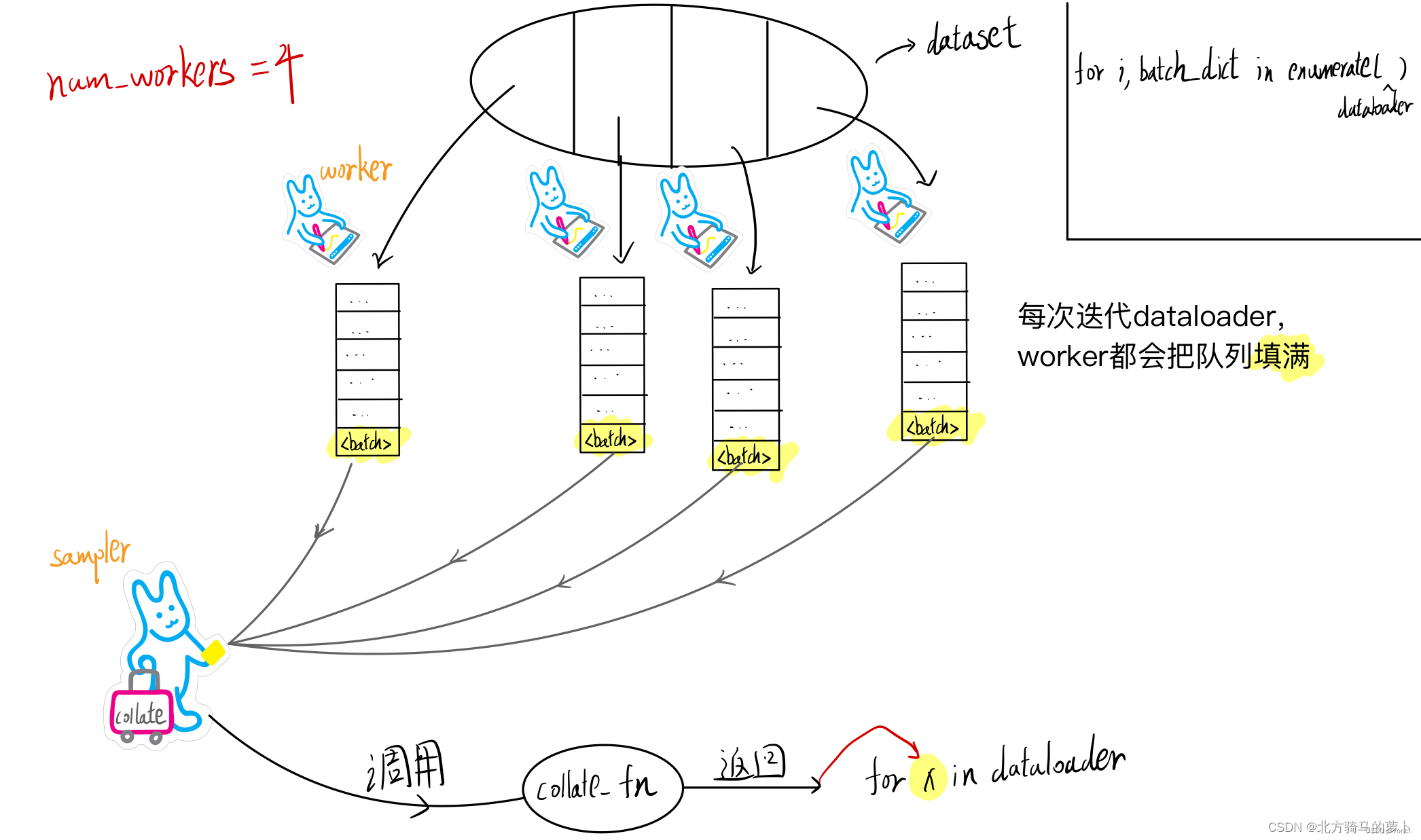
2.1 Hadoop框架概述 10
2.2 异构网络协同过滤推荐算法概念 11
2.3 异构网络协同过滤推荐算法技术原理 12
第三章 系统设计与实现 14
3.1 系统架构设计 14
3.2 数据预处理模块设计 15
3.3 算法实现与优化 16
3.4 系统功能与界面设计 17
第四章 实验与结果分析 19
4.1 实验设计 19
4.2 实验环境 21
4.3 实验结果分析 23
第五章 总结与展望 25
5.1 论文总结 25
5.2 研究不足与展望 25
第六章 参考文献 27
参考文献 27
摘要
随着互联网的快速发展,大数据技术和智能推荐系统在各个领域的应用越来越广泛。而针对异构网络的协同过滤推荐算法设计成为当前研究的热点之一。本文针对该问题,提出了一种基于Hadoop的异构网络协同过滤推荐算法设计。
首先,为了解决传统协同过滤算法在处理异构网络数据时的困难,本文使用了Hadoop平台进行大规模数据处理和分布式计算。通过Hadoop的分布式文件系统和MapReduce并行计算框架,可以高效地处理协同过滤算法所需的海量数据,提高算法的可扩展性和性能。
其次,本文针对异构网络的特点,设计了一种新的协同过滤推荐算法。该算法首先通过隐式反馈信息进行用户行为建模,提高了推荐准确性。然后,根据用户在不同网络之间的转换行为,构建了一个用户行为转换模型,用于更好地理解用户的兴趣变化和网络偏好。最后,通过结合基于用户和基于物品的协同过滤算法,实现了在异构网络中的精准推荐。
最后,本文通过实验验证了所提算法的有效性和优越性。与传统的协同过滤算法相比,基于Hadoop的异构网络协同过滤推荐算法在准确性和效率方面均取得了较好的结果。实验结果表明,该算法能够更好地满足用户的个性化需求,提供更精准的推荐结果。
综上所述,本文通过基于Hadoop的异构网络协同过滤推荐算法设计,解决了传统算法在处理异构网络数据时的问题,并在实验中取得了良好的效果。该研究对于推动大数据领域的发展和深入研究异构网络协同过滤算法具有一定的参考价值。
关键词
基于Hadoop, 异构网络, 协同过滤, 推荐算法, 设计
第一章 引言
1.1 研究背景
随着互联网和移动互联网技术的快速发展,大量的数据被迅速积累。然而,随着数据量的增加,如何从庞大的数据中提取出有用的信息成为一个挑战。推荐系统则应运而生,它利用用户历史行为和个性化需求,通过分析、挖掘和预测用户的偏好,为用户提供个性化的推荐服务。
目前,推荐系统已经成为电子商务、社会网络等领域中不可或缺的一部分。然而,传统的协同过滤推荐算法在处理大规模数据集时面临着效率低下的问题。为了解决这个问题,研究人员引入了分布式计算框架Hadoop,它能够利用集群的计算资源进行并行计算,提高推荐算法的计算效率。
然而,随着信息技术的快速演进,现有的推荐系统面临着一个新的挑战:异构网络。在现实生活中,不同类型的网络之间存在着复杂的关联关系,比如社交网络、物联网、传感器网络等。通过利用不同网络中的数据,可以更好地挖掘用户的兴趣和行为模式,提高推荐系统的准确性和个性化程度。
因此,本研究旨在基于Hadoop的异构网络协同过滤推荐算法设计。通过结合Hadoop分布式计算框架和协同过滤算法,研究如何利用异构网络中的数据进行推荐。具体来说,本研究将采用Hadoop的并行计算能力,从大规模异构网络中提取用户的行为数据,并将其应用于协同过滤算法中,实现个性化的推荐。
通过该研究,可以有效提高推荐系统的计算效率和推荐准确性,为用户提供更加精准和个性化的推荐服务。此外,本研究还将为推荐系统的进一步研究提供借鉴和参考,为推荐系统在处理大规模异构网络数据时提供新的思路和方法。
1.2 研究意义
随着互联网和大数据技术的快速发展,推荐系统已成为互联网应用中的重要组成部分。随之而来的是,对于传统的协同过滤推荐算法在大规模用户和物品数量下的计算效率和推荐准确度提出了更高的要求。同时,异构网络中的用户行为信息在推荐系统中亦具有重要价值。
本研究旨在设计一种基于Hadoop的异构网络协同过滤推荐算法,通过将大规模数据分布式存储和并行处理的特点应用于推荐系统,提高协同过滤推荐算法的效率和准确度。
首先,通过基于Hadoop分布式存储和计算框架,能够有效管理和处理大规模用户行为数据,提高推荐系统的响应速度和处理能力。Hadoop的分布式特性可以将数据分散存储于多个节点,并通过并行计算进行数据处理,大大提高了数据处理的效率和吞吐量。
其次,利用Hadoop的并行处理能力,可以更好地对异构网络中的用户行为数据进行挖掘和分析。由于异构网络中不同用户和不同网络环境下的行为特点各异,传统的协同过滤算法往往不能准确地捕捉到用户的兴趣和偏好。通过使用Hadoop,可以更细粒度地分析用户行为数据,并通过分布式计算得出更精准的推荐结果。
此外,通过在异构网络上应用协同过滤推荐算法,可以提高推荐结果的多样性和个性化程度。传统的协同过滤算法主要基于相似用户或物品的推荐策略,容易导致推荐结果的过度一致。而异构网络中的用户行为信息更加丰富多样,可以在推荐过程中引入更多的因素,从而提供更具多样性和个性化的推荐结果。
综上所述,基于Hadoop的异构网络协同过滤推荐算法的设计对于推荐系统的性能和准确度提升具有重要意义。通过充分利用Hadoop的分布式特性和并行处理能力,可以更好地处理大规模用户行为数据,挖掘用户的个性化偏好,提供高质量的推荐服务。