动机
在推荐系统中,交叉特征(Cross Features)可以深入挖掘特征之间的潜在关系,提升模型效果。例如,把职业特征 o c c u p a t i o n = { b a n k e r , d o c t o r } occupation=\left\{banker,doctor\right\} occupation={banker,doctor}和性别特征 g e n d e r = { M , F } gender=\left\{M,F\right\} gender={M,F}进行交叉组合,可以得到新特征 o c c u p a t i o n _ g e n d e r = { b a n k e r _ M , b a n k e r _ F , d o c t o r _ M , d o c t o r _ F } occupation\_gender=\left\{banker\_M,banker\_F,doctor\_M,doctor\_F\right\} occupation_gender={banker_M,banker_F,doctor_M,doctor_F}
Factorization Machine(FM)是挖掘交叉特征有代表性的模型,它的表达式如下:
y
F
M
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
v
i
T
v
j
⋅
x
i
x
j
y_{FM}(x) = w_0+\sum^n_{i=1}w_ix_i+\sum^n_{i=1}\sum^n_{j=i+1}v_i^Tv_j·x_ix_j
yFM(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nviTvj⋅xixj
上式中,
∑
i
=
1
n
w
i
x
i
\sum^n_{i=1}w_ix_i
∑i=1nwixi是一阶特征,
∑
i
=
1
n
∑
j
=
i
+
1
n
v
i
T
v
j
⋅
x
i
x
j
\sum^n_{i=1}\sum^n_{j=i+1}v_i^Tv_j·x_ix_j
∑i=1n∑j=i+1nviTvj⋅xixj是二阶交叉特征。FM的精髓在于用两个隐向量(
v
i
、
v
j
v_i、v_j
vi、vj)的内积来表示特征组合
<
x
i
,
x
j
>
<x_i,x_j>
<xi,xj>的权重。这种通过更新隐向量来更新组合权重的方式不需要保证该组合存在,从而使模型具有一定的泛化性。
本篇论文的作者认为,FM虽然具备较好的特征交叉能力,但是它的缺点也很明显:FM的特征交叉方式本质上是线性组合,并且特征交叉的阶数也局限于二阶,原因是如果阶数过高,会引发组合爆炸问题,带来巨大的计算负担。
针对上述问题,论文作者提出了Neural Factorization Machine(NFM)。该模型使用深度神经网络(DNNs)取代上面FM式子中的二阶项,让DNNs来负责特征交叉的建模,如下面式子所示:
y
F
M
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
f
(
x
)
y_{FM}(x) = w_0+\sum^n_{i=1}w_ix_i+f(x)
yFM(x)=w0+i=1∑nwixi+f(x)
同时,为了防止网络层数过深导致的退化问题,作者还设计了一种新的特征交叉网络层——Bi-Interaction Layer。
Neural Factorization Machine
NFM的网络架构图如下所示:
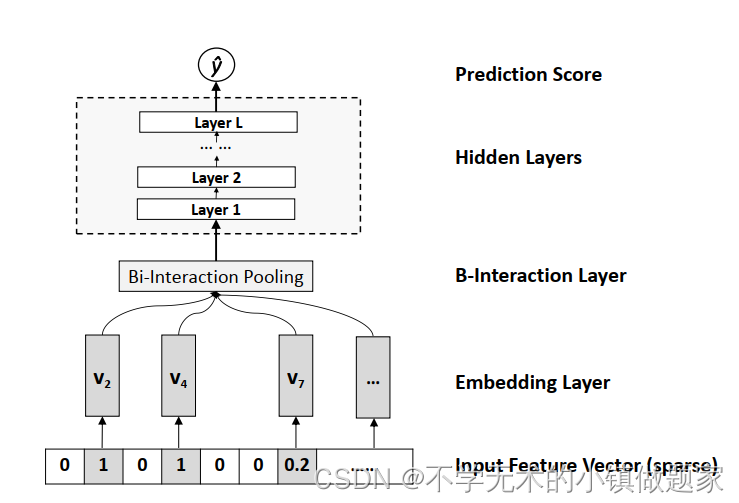
其实,上图中只画出了NFM的二阶特征交叉部分,一阶部分和FM类似,这里不再赘述。在NFM中,负责特征交叉的是B-Interaction Layer和Hidden Layers。
在B-Interaction Layer中,作者提出了一种名为Bi-Interaction Pooling的操作,表达式为:
f
B
I
(
V
x
)
=
∑
i
=
1
n
∑
j
=
i
+
1
n
x
i
v
i
⊙
x
j
v
j
f_{BI}(V_x) = \sum_{i=1}^n\sum_{j=i+1}^nx_iv_i⊙x_jv_j
fBI(Vx)=i=1∑nj=i+1∑nxivi⊙xjvj
其中
⊙
⊙
⊙是点对点乘积(element-wise product),
v
i
,
v
j
v_i,v_j
vi,vj分别是
x
i
,
x
j
x_i,x_j
xi,xj对应的隐向量。
HIdden Layers的表达式如下:
z
1
=
σ
1
(
W
1
f
B
I
(
V
x
)
+
b
1
)
z
2
=
σ
2
(
W
2
z
1
+
b
2
)
…
…
z
L
=
σ
L
(
W
L
z
L
−
1
+
b
L
)
z_1 = σ_1(W_1f_{BI}(V_x)+b_1) \\ z_2 = σ_2(W_2z_1+b_2) \\ ……\\ z_L=σ_L(W_Lz_{L-1}+b_L)
z1=σ1(W1fBI(Vx)+b1)z2=σ2(W2z1+b2)……zL=σL(WLzL−1+bL)
最后,向量
z
L
z_L
zL通过预测层得到最终的预测分数:
f
(
x
)
=
h
T
z
L
f(x) = h^Tz_L
f(x)=hTzL
总结
Neural Factorization Machine使用DNNs替换FM中的二阶交叉特征部分,使得网络能够突破阶数的限制,学习更加高阶的交叉特征。