文章目录
- 前言
- 1.建表并且生成一些数据
- 首先,建立一个用户文章操作表(user_article_operation)
- 使用case when语句简单分析数据
- 2. 代码与测试
- 只需要根据表生成相应实体类(注意要加一个value属性来存储分数)
- 主要代码如下,其实就两个方法
- userArticleOperationMapper.getAllUserPreference()方法收集数据mapper文件如下
- 测试算法
- 3.核心代码
- 4.相关参考
前言
我这里只是简单的跑了一下,仅供参考。。
这边只是跑了个文章推荐的demo,不过什么电影,商品啥的都一样,没啥区别
温馨提醒
这个mahout包有毒。。。。很多依赖冲突。。。。
这是我的pom文件,仅仅供参考。。
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.30</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
<!--引入推荐引擎mahout,注意要先全部引入,再使用exclusion标签-->
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-mr</artifactId>
<version>0.12.2</version>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jcl</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<artifactId>jersey-client</artifactId>
<groupId>com.sun.jersey</groupId>
</exclusion>
<exclusion>
<artifactId>jersey-core</artifactId>
<groupId>com.sun.jersey</groupId>
</exclusion>
<exclusion>
<artifactId>jersey-apache-client4</artifactId>
<groupId>com.sun.jersey.contribs</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
1.建表并且生成一些数据
首先,建立一个用户文章操作表(user_article_operation)

然后生成一些数据,这里使用navicat生成了50条记录(因为只是测试一下算法的准确性因此只生成了3个用户,10篇文章)
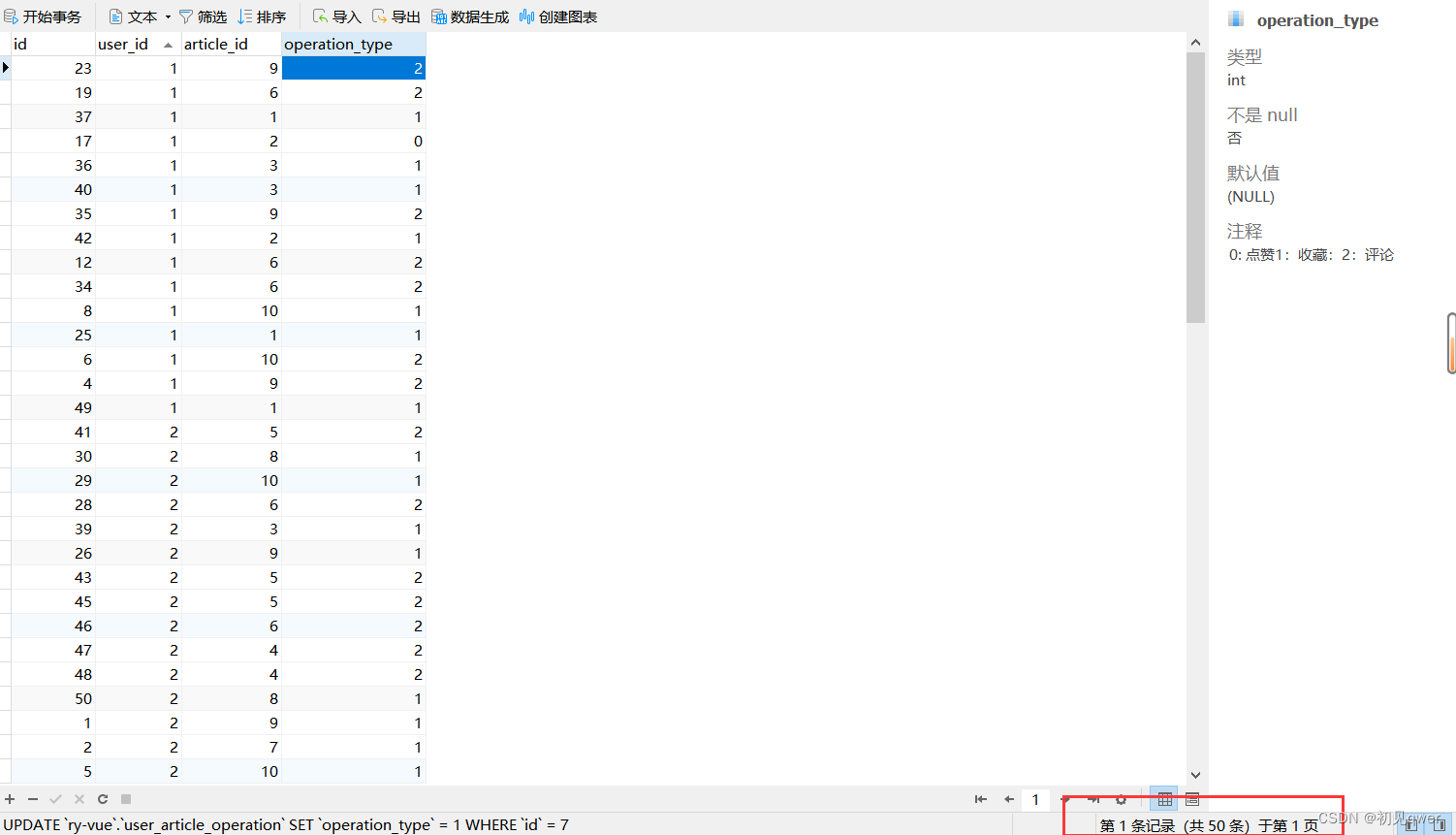
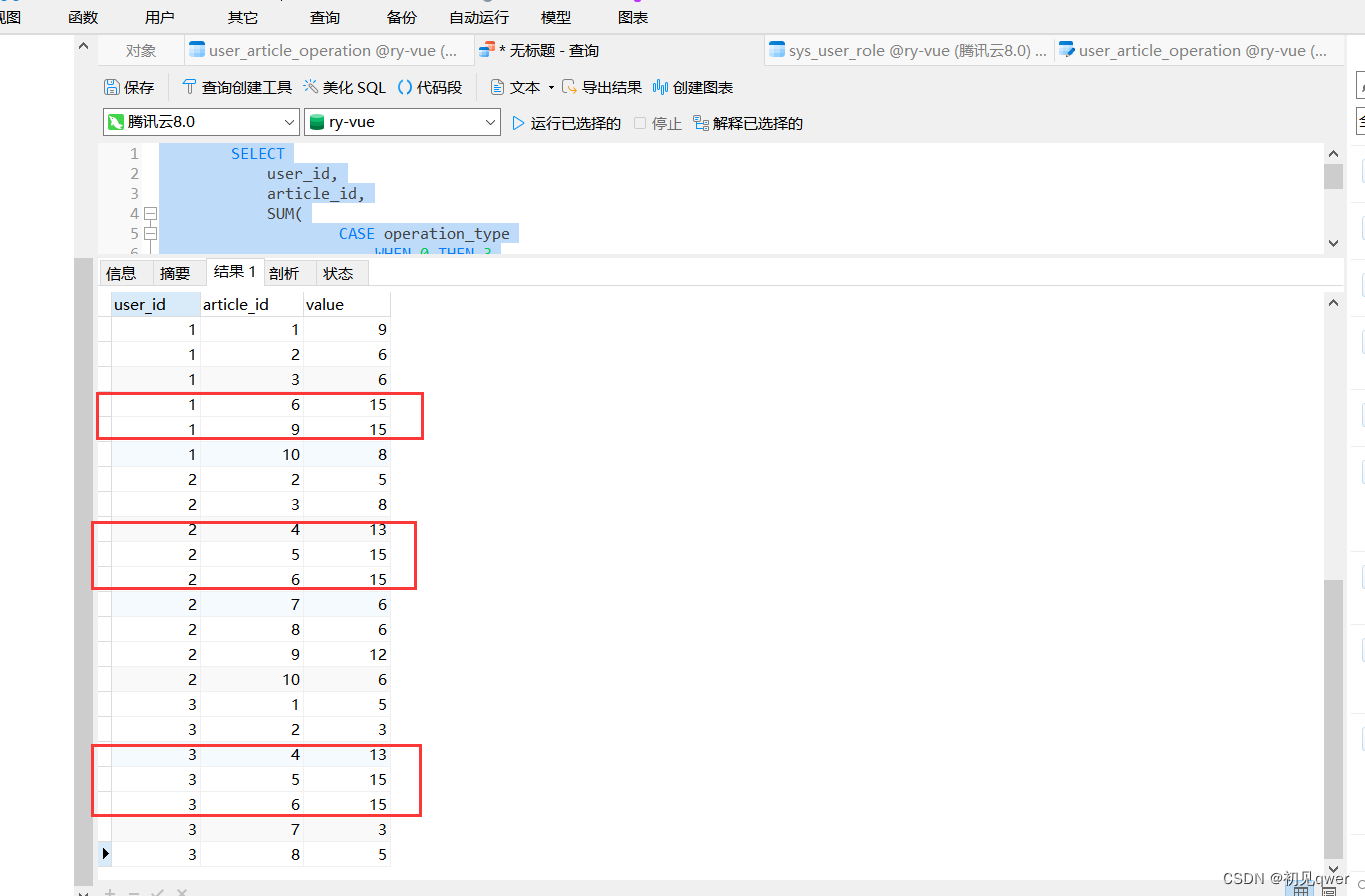
使用case when语句简单分析数据
SELECT
user_id,
article_id,
SUM(
CASE operation_type
WHEN 0 THEN 3
WHEN 1 THEN 3
WHEN 2 THEN 5
else 0 END
) AS "value"
FROM
user_article_operation
GROUP BY user_id,article_id
ORDER BY user_id
执行语句如下
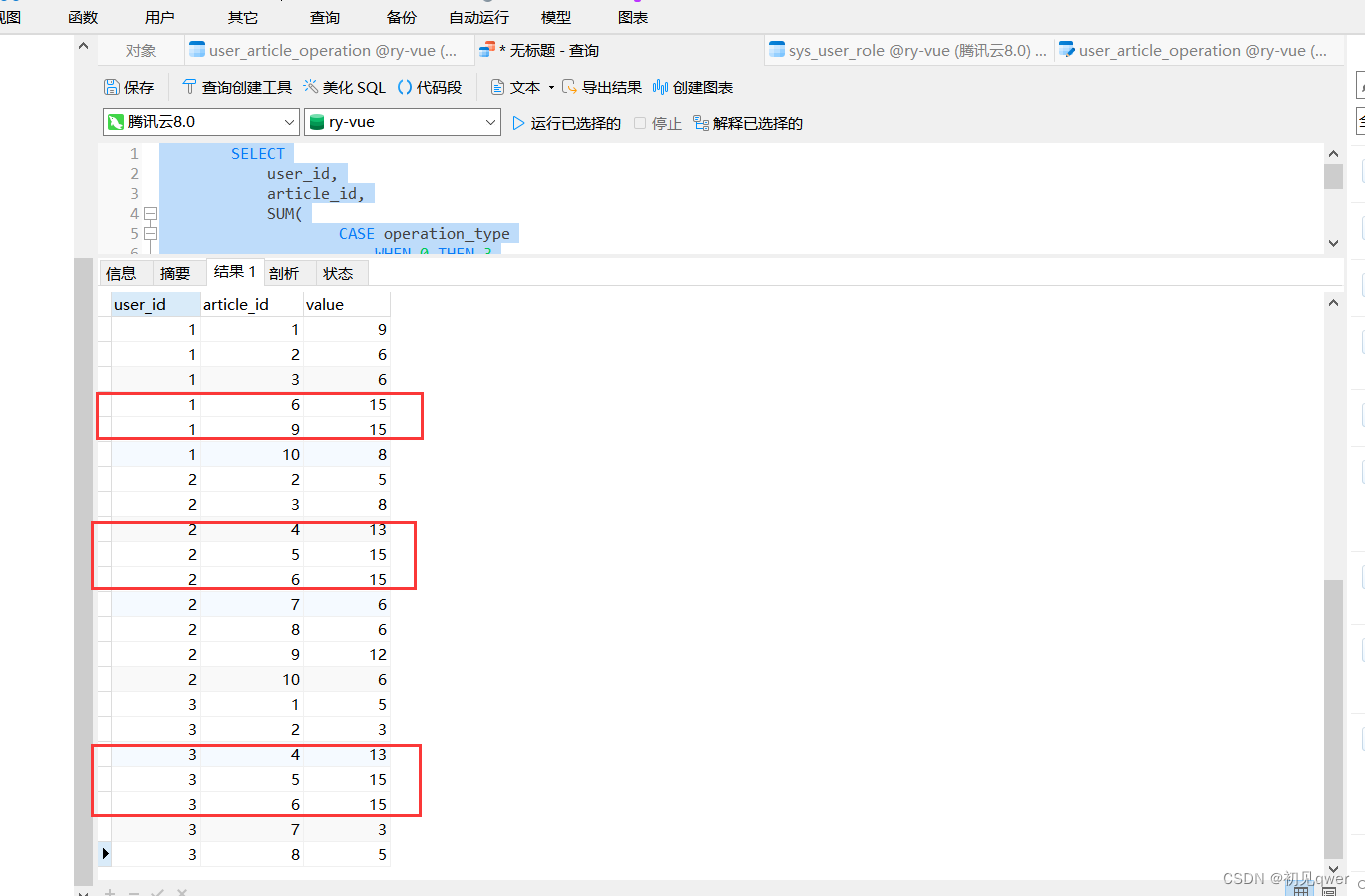
可以看出
1号用户最喜欢6,9号文章,
2号用户最喜欢4,5,6号文章
3号用户最喜欢4,5,6号文章
发现1,2,3号用户都喜欢6号文章,3个用户具有一定相似性。
(别问为啥这么规律,问就是我为了好测试修改了下数据,如果你感觉哪里不对劲的话,那你说的都对(反正我搞这个算法只是用来糊弄老师的😂😂😂))
因此如果要给1号用户推荐文章的话,应该先推荐5号,再推荐4号文章。
2. 代码与测试
只需要根据表生成相应实体类(注意要加一个value属性来存储分数)
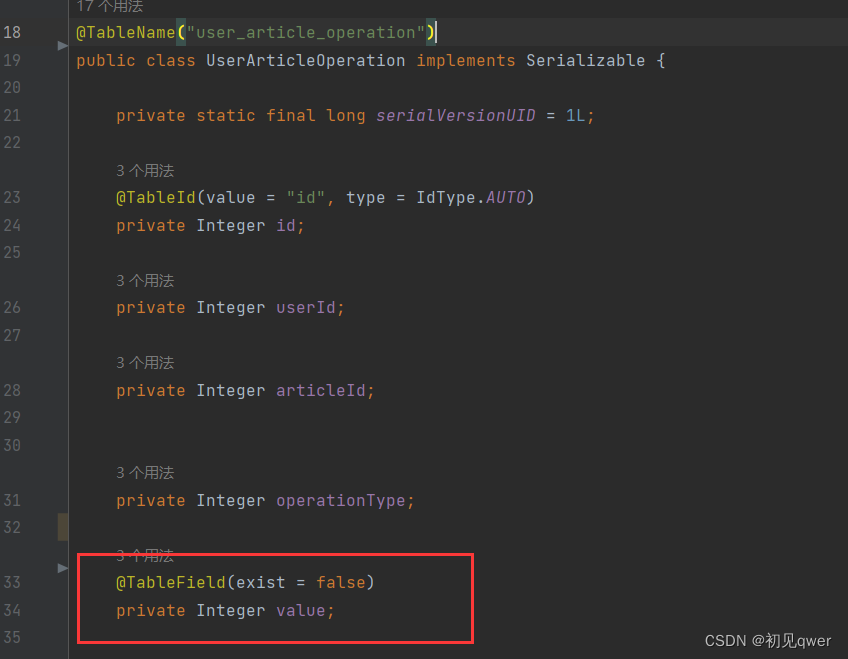
主要代码如下,其实就两个方法

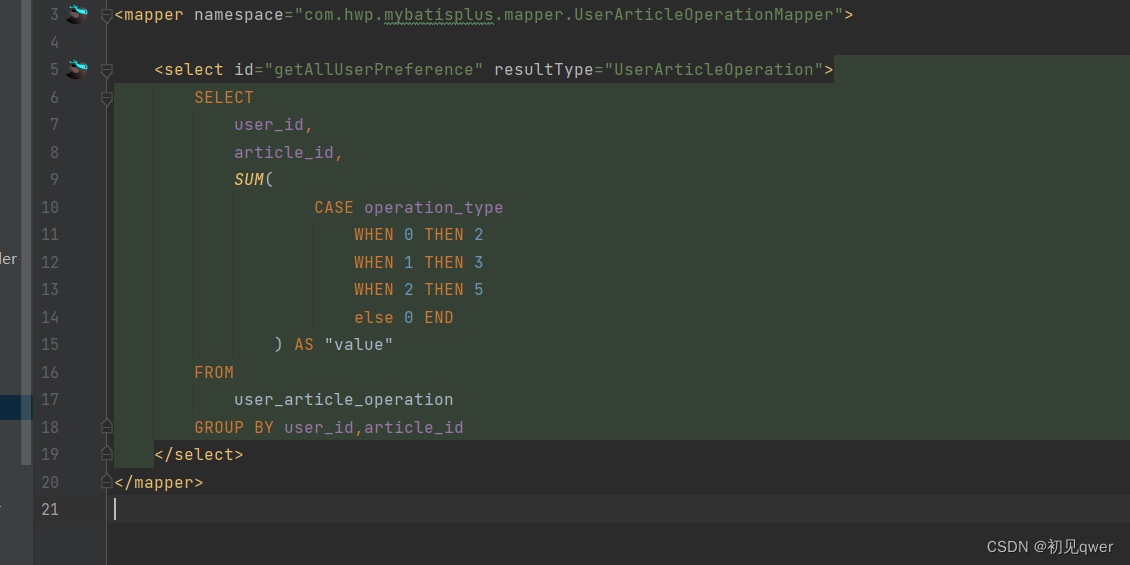
userArticleOperationMapper.getAllUserPreference()方法收集数据mapper文件如下
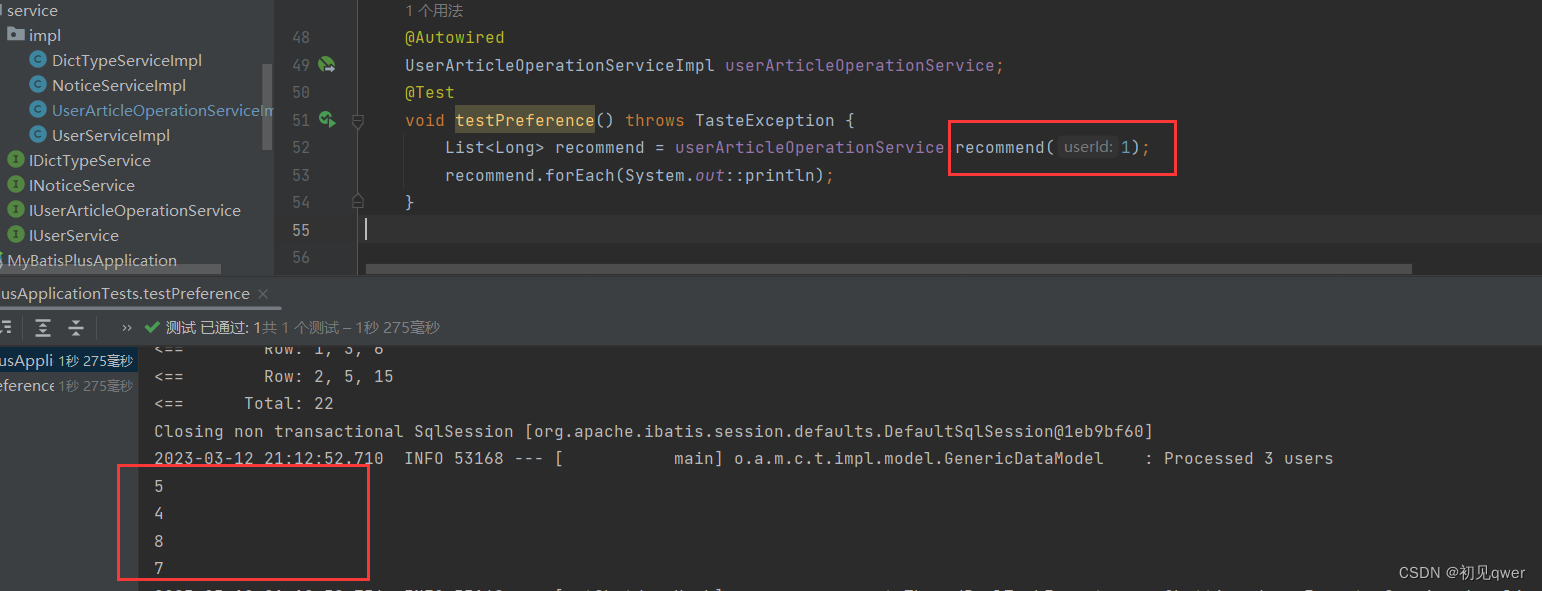
测试算法
输入推荐5个,但是这里只推荐了四个,应该是样本数据量太小的原因,对比了一下之前运行case when语句时做的的简单预测,5号最推荐,然后是4号,控制台打印的结果还是比较符合的。
(反正糊弄一下老师够了,这里只是提供一个小demo,读者需注意哈🚗🚗🚗🚗)
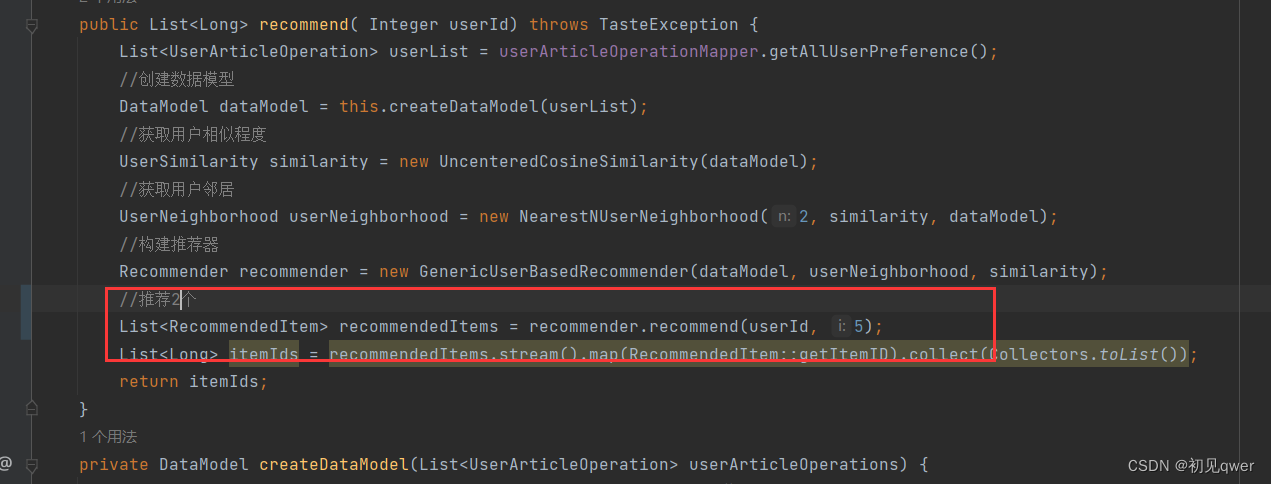
3.核心代码
public List<Long> recommend( Integer userId) throws TasteException {
List<UserArticleOperation> userList = userArticleOperationMapper.getAllUserPreference();
//创建数据模型
DataModel dataModel = this.createDataModel(userList);
//获取用户相似程度
UserSimilarity similarity = new UncenteredCosineSimilarity(dataModel);
//获取用户邻居
UserNeighborhood userNeighborhood = new NearestNUserNeighborhood(2, similarity, dataModel);
//构建推荐器
Recommender recommender = new GenericUserBasedRecommender(dataModel, userNeighborhood, similarity);
//推荐2个
List<RecommendedItem> recommendedItems = recommender.recommend(userId, 5);
List<Long> itemIds = recommendedItems.stream().map(RecommendedItem::getItemID).collect(Collectors.toList());
return itemIds;
}
private DataModel createDataModel(List<UserArticleOperation> userArticleOperations) {
FastByIDMap<PreferenceArray> fastByIdMap = new FastByIDMap<>();
Map<Integer, List<UserArticleOperation>> map = userArticleOperations.stream().collect(Collectors.groupingBy(UserArticleOperation::getUserId));
Collection<List<UserArticleOperation>> list = map.values();
for(List<UserArticleOperation> userPreferences : list){
GenericPreference[] array = new GenericPreference[userPreferences.size()];
for(int i = 0; i < userPreferences.size(); i++){
UserArticleOperation userPreference = userPreferences.get(i);
GenericPreference item = new GenericPreference(userPreference.getUserId(), userPreference.getArticleId(), userPreference.getValue());
array[i] = item;
}
fastByIdMap.put(array[0].getUserID(), new GenericUserPreferenceArray(Arrays.asList(array)));
}
return new GenericDataModel(fastByIdMap);
}
<select id="getAllUserPreference" resultType="UserArticleOperation">
SELECT
user_id,
article_id,
SUM(
CASE operation_type
WHEN 0 THEN 2
WHEN 1 THEN 3
WHEN 2 THEN 5
else 0 END
) AS "value"
FROM
user_article_operation
GROUP BY user_id,article_id
</select>
4.相关参考
1.spring boot项目基于mahout推荐算法实现商品推荐
2.相关内容在章节5-9